
-
资源
- 网上比较完整统一的资料不是很多,很多文章感觉也说得不是很清楚,或者版式体验真不太好。 主要就找到两本书籍,一本英文,一本才出不久的中文, 第二本还在路上,就先用第一本过过瘾。这本英文书主要就三个部分,所以希望能用几篇文章来记录,还有个地方就是官网。
-
源代码
- 建议把源代码拿到,以备不时之需。
- 这样就可以将源代码Import到Eclipse中了(请用Java Compile Level调整到1.7以上)。
-
简介
-
"Zookeeper"由来
- 作者讲述了"Zookeeper"名称由来。Zookeeper是伴随Hadoop产生的, 而Hadoop生态系统中,很多项目都是以动物来命名,如Pig,Hive等, 似乎像一个动物园,这样就得到动物园管家的名称"Zookeeper"。
-
同步原语
-
元数据配置
-
Zookeeper应用
-
通过Zookeeper Client API我们可以做什么
-
Zookeeper不能做什么
-
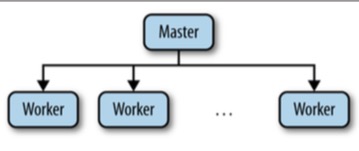
案例: 典型的Master-Worker架构
- Master-Worker架构是比较有代表性的,其中阐述了很多常用的功能,如 Master选举,跟踪可用的Worker,维护应用元数据。 在Master-Worker架构,我们需要解决三个关键的问题
- 针对上面的问题,我们需要做到以下几点
- 最后,被作者这句话所打动
-
开始使用Zookeeper
- 之前讲述了协调在分布式应用中的重要性,也列举了会遇到的一些通用问题,接下来我们将开始接触 Zookeeper。
-
Zookeeper基础
- Zookeeper本身并没有提供一些原语操作,如分布式锁,而是,暴露一些类似文件系统的API,用于操作一些小的数据节点,叫做 Znode,这些节点组成了一棵层级树,如Master-Worker架构中
- Znode数据缺失往往会透露出重要的信息, 如master节点缺失就意味着当前没有master节点被选举出,上图也说明
-
API概览
- Znode可以存储二进制数据, Zookeeper并没有直接提供解析二进制数据的功能,这需要我们自己根据应用来转译对应的二进制数据。 Zookeeper Client主要提供了以下API:
-
不同模式的节点
- 持久节点和临时节点。
-
连续节点
-
监听(Watches)和通知(Notifications)
- 在Zookeeper中频繁访问节点及数据是耗资源,将导致很高的延迟,如图, 多次调用getChildren()返回的值却一样,而这种重复调用是没有必要的
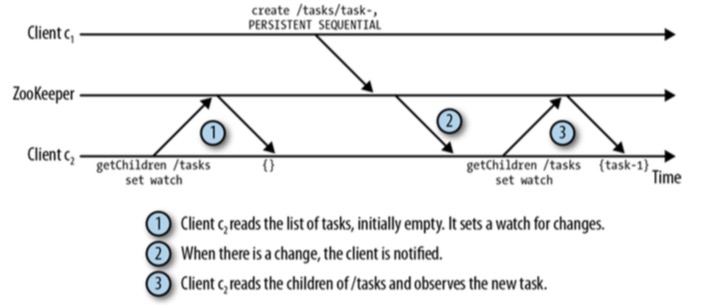
- 这是因为采用的是Polling模式,而Zookeeper 采用的是Notifications机制:客户端通过注册来接收节点变化的通知。注册接收通知通过Watch 来设置。而Watch是一次性操作,也就是只能接收一次通知,如果需要继续得到通知, 则需要再次Watch。
- 由于通知是一次性操作,因此某些情况会有一些问题,如
- 上述的问题,我们可以在客户端c1设置完Watch后,读取一次/tasks的状态,这样就能防止丢失更新通知。 尽管这样可能导致Zookeeper的状态改变分发变慢,但是更重要的是, 这样使得所有客户端可以统一顺序感知到Zookeeper的状态改变,这是十分关键的。
- Zookeeper支持多种通知,这要看客户端Watch什么样的事件,如 节点数据改变,子节点改变, 节点删除,节点创建等, Zookeeper提供了Watcher对象来调用对应API, 后面会详述该对象。
-
版本号(Versions)
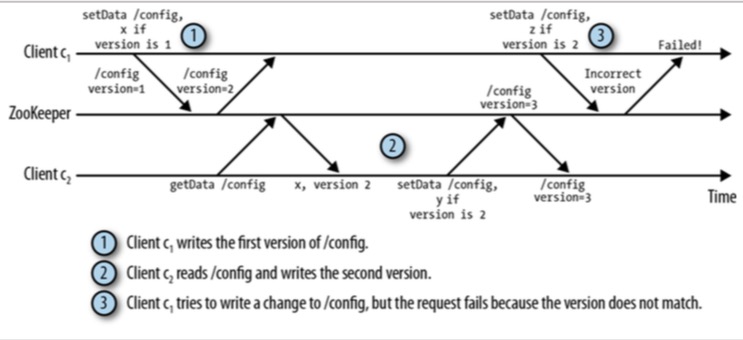
- Zookeeper中每个节点都有一个版本号(version)与之关联,每当节点数据发生变化时, 版本号将递增,其中setData()和delete() 两个API需要带上版本号作为输入参数,在做更新前,Zookeeper 会比较客户端传来的version和当前服务器的version是否一致,不一致则会操作失败,这就有效阻止了数据非一致性,如
-
Zookeeper架构
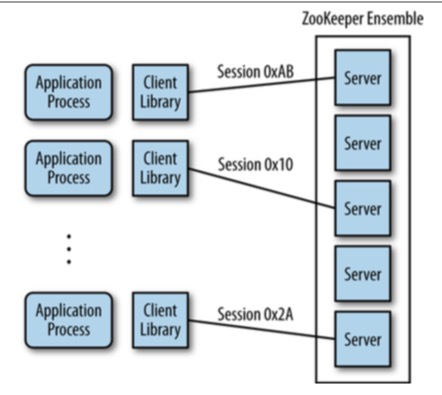
- 在使用Zookeeper中,我们都是通过Zookeeper Client API 与Zookeeper Server进行交互,下图则说明了Client和Server之间的关系
- Zookeeper以两种方式运行:Standalone和Quorum。 Standalone模式下,仅有一个Zookeeper服务器,Zookeeper状态不会被复制。 Quorum机制,是一种分布式系统中常用的,用来保证数据冗余和最终一致性的投票算法。 Quorum模式下,一组Zookeeper服务器,状态会被复制,并一同为客户端提供服务。
-
Zookeeper Quorums
-
会话(Sessions)
- 在执行任何请求前,客户端必须先与Zookeeper集群建立回话(Session)。 会话提供了有序保证,即同一会话中请求将以FIFO的顺序被执行。 但当客户端并发开启多个会话,将不能跨会话保证FIFO顺序。
-
开始使用Zookeeper
- 在这里下载,解压并安装。
- 这样客户端就能与Zookeeper交互了
- 简单执行几个命令
-
会话的状态和生命周期
- 会话主要有四个状态: NOT_CONNECTED, CONNECTING, CONNECTED, CLOSED, 会话状态转换图为
- 解释下这几个状态
- Client会话建立过程
- Client重连机制
-
Zookeeper集群
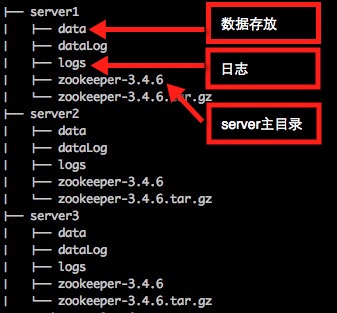
- 首先准备几个Server的目录
- Server主配置zoo.cfg
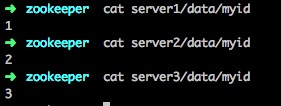
- 在每个Server/data目录下建立一个myid文件,标识自己是哪个Server(对应zoo.cfg的server列表)
- 现在启动server1
- server1尝试连接zoo.cfg中配置的server列表,这时server2,server3还没启动,因此连接失败, 将server2,server3一并启动后,可以看到server1已经成为Follower
- 于是,可以使用客户端尝试连接这个集群,并且客户端会被随机分配到一个server
-
Zookeeper分布式锁实现
-
Master-Worker实现
- 这里仅仅是使用zkCli.sh工具来实现,达到阐述原理的目的,代码实现放在下一篇文章中
- 第一个会话创建一个叫/master的临时节点
- 假设现在还有另一个进程作为master备份节点,开始创建master节点,却被告知master节点已经存在
- 但有可能在某一瞬间主master就崩溃了,这时备份master应立即转为主master,所以我们需要Watch主master
- stat命令可以获取节点的属性,并且监听其是否存在,参数true表明设置Watch。 这时,主master突然崩溃断开连接(第一个的会话),这时第二个会话将得到节点/master删除的通知,并立即转为主master
-
工作者(Workers),任务(Tasks)和分配(Assignments)
- 先建立分别存在Workers,Tasks和Assignments的节点:/workers,/tasks,/assign。(注意是持久节点)
- 现在我们的master节点需要监听到节点/workers和/tasks,以便分配task到worker
- ls命令带上true参数,表明Watch该节点的子节点变化。
-
Worker角色
- 打开另一个会话,假设现在有一个worker可用
- 此时master也得到/workers子节点变化的通知
- 为了收到分配的任务,worker需要创建一个节点 /assign/worker1.example.com,并且监听子节点的变化
- Client角色
- 现在假设一个客户端提交了一个任务到服务器中, 并且它必须还得监听该任务节点, 因为客户端必须知道自己提交的任务到底被执行或执行成功没有
- 这里我们创建了一个连续持久节点,因此其节点名称加上了一个递增整数0000000000, 这时,master节点就感知到有新的任务提交上来了,将其分配给worker1
- 然后master节点检查新的任务,可用的worker节点,并分配任务给worker
- 于是,worker节点感知到了分配给自己的任务,并做检查
- worker一旦完成了任务,将在对应的任务下增加一个状态节点
- 此时客户端将得到通知,并检查任务执行结果
- 于是,客户端就知道了任务被执行的结果,这里结果为"done", 表示任务被成功执行。
前两天被问到有关Zookeeper的一些问题,但确没有很好的回答上来。 之前也接触过Zookeeper,比如使用其Watcher实现一些通知, 或者Leader选举功能,也可以作为如Dubbo服务框架的注册中心等, 但是对Zookeeper的运作原理等是不太了解的,也没有认真仔细研究过, 特此希望通过阅读和记录文章,深入理解一番Zookeeper,觉得其中很多分布式的思想,会对自己有很大的帮助。


git clone [email protected]:apache/zookeeper.git
cd zookeeper
ant eclipse
就像螺丝刀对螺丝,螺丝刀可以转动螺丝,但这并不能完全说明它的功能,更重要的是它可以组装我们的家具和电子设备等。 而Zookeeper则可以在 分布式系统中帮助我们协调任务。
在典型的Master-Worker架构中, Worker需要告诉Master自己可以接受任务, 然后Master将分配任务给Worker。 又例如,在多线程上下文中有用的同步原语在分布式系统中同样也有用,但有一个重要的区别, 在无共享架构中,不同的机器除了共享网络外,不会共享其他任何东西。 虽然有很多消息传递算法可以实现同步原语,但是通过一些提供共享存储和有序属性的组件来实现会更容易一些, Zookeeper就是这样做的。
协调也不总是同步原语的形式, 比如Leader选举或者锁, 而元数据配置通常用来实现传递别人应该做什么,比如,Master-Worker架构中, Worker需要知道分配给它的任务,即便Master崩溃了。
1. Apache HBase。HBase中,Zookeeper用于选举集群Master,跟踪可用的Server,和保存集群元数据。
2. Apache Kafka。Kafka中,Zookeeper用于崩溃检测,实现Topic发现,和维护Topic的生产和消费状态。
3. Apache Solr。Solr中,Zookeeper用于存储集群的元数据信息及协调元数据的更新。
4. Yahoo!Fetching Server。Fetching Service中,Zookeeper用于Master选举,崩溃检测,元数据保存。
5. Facebook Messages。Messages中,Zookeeper用于实现分片和故障迁移的控制器,和服务发现。
...
1. 强一致,有序性和持久化操作。
2. 典型的同步原语实现。
3. 在分布式系统中,更容易处理往往不正确的并发行为。
Zookeeper不适合用于大容量存储。对于大容量存储 ,我们完全可以考虑使用数据库或者分布式文件系统等,重要的是,我应该将业务数据 和 用于协调和控制的数据分离。Zookeeper本身并没有提供如 Master选举,跟踪活动进程的功能,而是提供一些实现这些功能的工具。
1. Master崩溃。Master一旦崩溃,系统将不能在分配新任务或者重新分配来自Worker的任务。
2. Worker崩溃。Worker一旦崩溃,那么分配给它的任务将不能被完成。
3. 通信失败。Master和Worker之间不能交换信息,Worker将不能学习分配给它的新任务。
1. Master选举。让可用的Master分配任务给Worker的过程是至关重要的。
2. 崩溃检测。Master必须能检测Worker什么时候崩溃或者不可连接。
3. 组成员管理。Master必须能知道哪些Worker可以执行任务。
4. 元数据管理。Master和Worker必须能以可靠的方式存储任务分配和执行状态的信息。
so easily, in fact, that some developers use it without completely understanding some of the cases that require the developer to make decisions that ZooKeeper cannot make by itself. One of the purposes of writing this book is to make sure that developers understand what they need to do to use ZooKeeper effectively and why they need to do it that way.
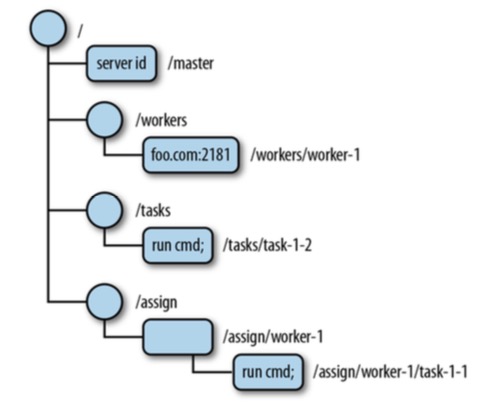
1. /workers节点下的是所有worker节点,图中表明foo.com:2181的worker节点可用。
若worker不可用了,将从/workers下移除。
2. /tasks节点下的是所有创建的和等待被执行的任务节点,每当客户端向Master提交任务时,将在/tasks下添加新的任务节点。
3. /assign节点下的是分配给woker节点的任务。
create /path data
创建节点/path, 并存储数据data
delete /path
删除节点/path
exists /path
检查节点/path是否存在
setData /path data
设置节点/path的数据
getData /path
获取节点/path的数据
getChildren /path
获取节点/path的子节点
持久节点只能通过delete调用才能删除, 可用于存储一些应用数据(即使它的创建者不存在了,但这些数据依然需要保存),如Master-Worker中的任务分配信息。 而临时节点,会在客户端崩溃或断开连接时被删除,或者通过delete调用。比如, 在Master-Worker中的Master和Worker节点均采用临时节点,当Master崩溃或连接断开, 该节点将自动删除,既而才能进行Master选举,临时节点暂时还不支持有子节点,即便以后支持, 其子节点也必须是临时节点。
一个Znode可以被设置为sequential,连续节点将被分配一个唯一且连续的整数,
该整数会追加到节点的path后,如客户端创建一个path为/task/task-的连续节点,最终节点的path会变成/task/task-1。
综上,Zookeeper节点支持四种模式:
持久节点,临时节点,持久连续节点,临时连续节点。
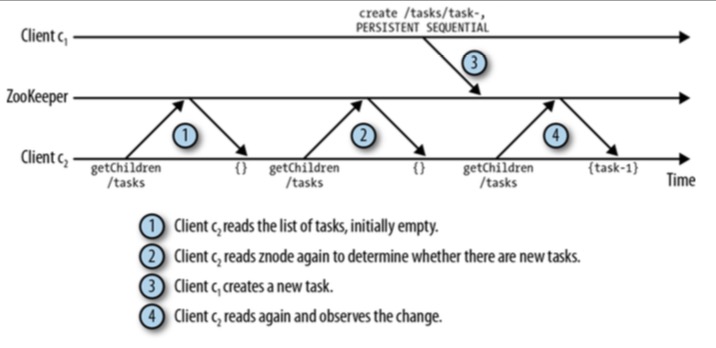
1. 客户端c1对节点/tasks设置了Watch
2. 客户端c2在节点/tasks添加了新节点
3. 客户端c1收到了通知
4. 客户端c1设置新的Watch, 但在设置之前, 客户端c3在节点/tasks添加了新的节点
5. 此时客户端c1就丢失了来自客户端c3的更新通知
Quorum模式下,Zookeeper复制树节点数据到所有的Server。 但是不是说需要等待所有数据复制到所有Server后,才能响应客户端请求继续,往往quorum会比较小,比如,我们的Zookeeper集群有 5个Server,而quorum=3,那么只要有3个Server已经有复制的数据了,就能让客户端继续操作,而其他两个Server最终会同步到数据。 大多数情况下,我们容忍小于N/2个Server崩溃,集群建议用奇数个Server组成。
tar -xvzf zookeeper-3.4.5.tar.gz
cd zookeeper-3.4.6
# zookeeper配置文件
mv conf/zoo_sample.cfg conf/zoo.cfg
# 设置zoo.cfg的dataDir
dataDir=~/path/to/data
# 启动zookeeper,start-foreground表示ZK运行在前台
bin/zkServer.sh [start-foreground]
# 运行客户端
bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[dubbo, zookeeper, pampas, pubsub]
[zk: localhost:2181(CONNECTED) 1] create /workers ""
Created /workers
[zk: localhost:2181(CONNECTED) 2] ls /
[dubbo, zookeeper, workers, pampas, pubsub]
[zk: localhost:2181(CONNECTED) 3] delete /workers
[zk: localhost:2181(CONNECTED) 4] ls /
[dubbo, zookeeper, pampas, pubsub]
[zk: localhost:2181(CONNECTED) 5] quit
# 停止Server
bin/zkServer.sh stop
1. Client初始化连接,状态转为CONNECTING(①)
2. Client与Server成功建立连接,状态转为CONNECTED(②)
3. Client丢失了与Server的连接或者没有接受到Server的响应,状态转为CONNECTING(③)
4. Client连上另外的Server或连接上了之前的Server,状态转为CONNECTED(②)
5. 若会话过期(是Server负责声明会话过期,而不是Client ),状态转为CLOSED(⑤),状态转为CLOSED
6. Client也可以主动关系会话(④),状态转为CLOSED
在Client创建会话时,可以指定超时时间T,若Server在T内没有收到客户端任何消息,将认为会话过期。 而对于Client,若在在T/3时没有收到Server的响应,将发送一个心跳信息给Server, 在2/3T时刻还是没有收到Server的响应,则会尝试重连其他Server(这样就还有T/3时间查找另外的Server)。
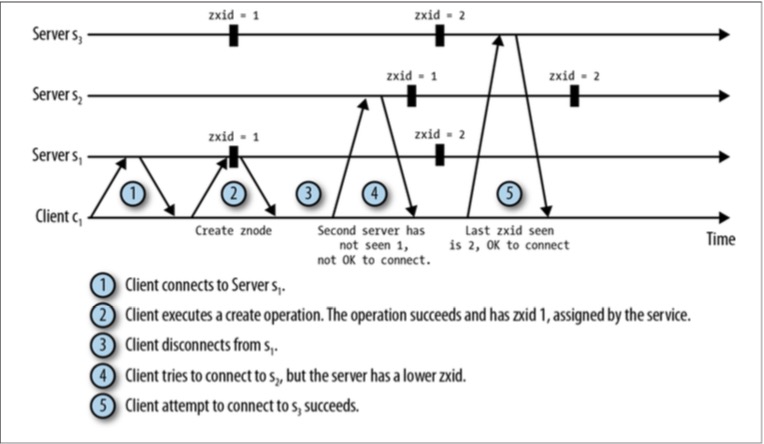
在Client重连不同的Server时,该Server的状态必须同该Client观察到的Server状态一致(或者更新),这一点很重要。 Client不能连接上状态过时的Server(没有看到该Client已经看到的服务器状态变化)。在Zookeeper实现中, 系统会为每一个更新连接分配一个有序的事务标识符(zxid),这样就能保证Client不会重连上比自己过时的Server,如图
# 心跳间隔时间(ms)
tickTime=2000
# Follower与Leader初始化时能容忍的时间(initLimit * tickTime)
initLimit=10
# Follower与Leader请求响应时能容忍的时间(syncLimit * tickTime)
syncLimit=5
# server1数据目录,每个server各自配置
dataDir=/path/to/server1/data
# 客户端连接端口
clientPort=2182
# server列表:
# .n(标记server)=(server地址):(投票时所用端口):(选举Leader时所用端口)
server.1=127.0.0.1:2889:3889
server.2=127.0.0.1:2990:3990
server.3=127.0.0.1:2991:3991
server1/zookeeper-3.4.6/bin/zkServer.sh start-foreground
# 输出
2015-03-02 19:56:47,485 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2182:QuorumPeer@714] - LOOKING
2015-03-02 19:56:47,486 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2182:FastLeaderElection@815] - New election. My id = 1, proposed zxid=0x1a00000006
2015-03-02 19:56:47,488 [myid:1] - INFO [WorkerReceiver[myid=1]:FastLeaderElection@597] - Notification: 1 (message format version), 1 (n.leader), 0x1a00000006 (n.zxid), 0x1 (n.round), LOOKING (n.state), 1 (n.sid), 0x1a (n.peerEpoch) LOOKING (my state)
2015-03-02 19:56:47,510 [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@382] - Cannot open channel to 2 at election address /127.0.0.1:3990
java.net.ConnectException: Connection refused
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:345)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:589)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.toSend(QuorumCnxManager.java:341)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.process(FastLeaderElection.java:449)
at org.apache.zookeeper.server.quorum.FastLeaderElection$Messenger$WorkerSender.run(FastLeaderElection.java:430)
at java.lang.Thread.run(Thread.java:744)
2015-03-02 19:56:47,560 [myid:1] - WARN [WorkerSender[myid=1]:QuorumCnxManager@382] - Cannot open channel to 3 at election address /127.0.0.1:3991
2015-03-02 20:02:41,487 [myid:1] - INFO [/127.0.0.1:3889:QuorumCnxManager$Listener@511] - Received connection request /127.0.0.1:65469
2015-03-02 20:02:41,492 [myid:1] - INFO [WorkerReceiver[myid=1]:FastLeaderElection@597] - Notification: 1 (message format version), 3 (n.leader), 0x1a00000006 (n.zxid), 0x1 (n.round), LOOKING (n.state), 3 (n.sid), 0x1a (n.peerEpoch) FOLLOWING (my state)
server1/zookeeper-3.4.6/bin/zkCli.sh -server 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184
虽然Zookeeper没有原生提供锁操作,但是通过Zookeeper提供的一些API, 较容易实现分布式锁。我们可以利用临时节点来实现,多个进程都尝试创键临时节点/lock, 但最终只会有一个进程P能创建成功,而其他没能创建成功的进程,可以在节点/lock上Watch(相当于等待锁释放), 一旦进程P处理完事务,断开连接,节点/lock被自动删除,其他进程将得到通知,进而继续创建节点/lock,以争得锁资源。 (这里使用临时节点,是为了防止获得锁的进程突然崩溃而没有释放锁,导致死锁发生)。
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 3] create -e /master "master1.example.com:2223"
Created /master
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 4] ls /
[zookeeper, master]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 5] get /master
"master1.example.com:2223"
cZxid = 0x1b00000002
ctime = Mon Mar 02 20:39:06 CST 2015
mZxid = 0x1b00000002
mtime = Mon Mar 02 20:39:06 CST 2015
pZxid = 0x1b00000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x34bda5de5120000
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 1] create -e /master "master2.example.com:2223"
Node already exists: /master
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 1] create -e /master "master2.example.com:2223"
Node already exists: /master
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 2] stat /master true
cZxid = 0x1b00000002
ctime = Mon Mar 02 20:39:06 CST 2015
mZxid = 0x1b00000002
mtime = Mon Mar 02 20:39:06 CST 2015
pZxid = 0x1b00000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x34bda5de5120000
dataLength = 26
numChildren = 0
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 0] ls /
[zookeeper, master]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 1] create -e /master "master2.example.com:2223"
Node already exists: /master
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 2] stat /master true
cZxid = 0x1b00000002
ctime = Mon Mar 02 20:39:06 CST 2015
mZxid = 0x1b00000002
mtime = Mon Mar 02 20:39:06 CST 2015
pZxid = 0x1b00000002
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x34bda5de5120000
dataLength = 26
numChildren = 0
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 3]
WATCHER::
WatchedEvent state:SyncConnected type:NodeDeleted path:/master
ls /
[zookeeper]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 4] create -e /master "master2.example.com:2223"
Created /master
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 5] ls /
[zookeeper, master]
zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 6] create /workers ""
Created /workers
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 7] create /tasks ""
Created /tasks
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 8] create /assign ""
Created /assign
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 9] ls /
[zookeeper, workers, tasks, master, assign]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 10] ls /workers true
[]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 11] ls /tasks true
[]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 0] create -e /workers/worker1.example.com "worker1.example.com:2224"
Created /workers/worker1.example.com
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 12]
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/workers
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 1] create /assign/worker1.example.com ""
Created /assign/worker1.example.com
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 2] ls /assign/worker1.example.com true
[]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 3]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 0] create -s /tasks/task- "cmd"
Created /tasks/task-0000000000
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 1] ls /tasks/task-0000000000 true
[]
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/tasks
ls /tasks
[task-0000000000]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 13] ls /workers
[worker1.example.com]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 14] create /assign/worker1.example.com/task-0000000000 ""
Created /assign/worker1.example.com/task-0000000000
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/assign/worker1.example.com
ls /assign/worker1.example.com
[task-0000000000]
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 4] create /tasks/task-0000000000/status "done"
Created /tasks/task-0000000000/status
WATCHER::
WatchedEvent state:SyncConnected type:NodeChildrenChanged path:/tasks/task-0000000000
get /tasks/task-0000000000
"cmd"
cZxid = 0x1b0000000e
ctime = Mon Mar 02 23:26:43 CST 2015
mZxid = 0x1b0000000e
mtime = Mon Mar 02 23:26:43 CST 2015
pZxid = 0x1b00000010
cversion = 1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 5
numChildren = 1
[zk: 127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184(CONNECTED) 3] get /tasks/task-0000000000/status
"done"
cZxid = 0x1b00000010
ctime = Mon Mar 02 23:52:18 CST 2015
mZxid = 0x1b00000010
mtime = Mon Mar 02 23:52:18 CST 2015
pZxid = 0x1b00000010
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 6
numChildren = 0
以上就是整个Master-Worker架构的主要工作机制,虽然只是一个模拟过程, 但是对我们理解Master-Worker工作原理是很有帮助的,对以后要研究代码实现,也是一个很好的铺垫。

