-
使用Zookeeper API
-
首先添加Maven依赖
-
创建Zookeeper会话
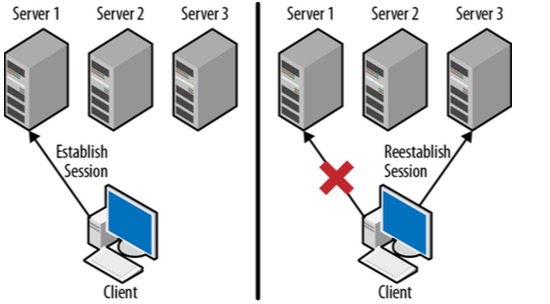
- Zookeeper API会围绕一个Zookeeper 句柄,通过该句柄来调用各种API,该句柄也就是 Zookeeper会话。如果会话连接断开了,该会话会被迁移到另一台Server上(如图),只要会话仍然存活着, 该句柄将一直有效,Client就会持续保持和Server的连接,若句柄被关掉,Client将告诉Server关掉会话。
- Zookeeper提供了一个创建句柄的构造器
-
实现Watcher
- 为了收到Zookeeper的通知,我们需要实现Watcher接口
- 比如,我们可以实现一个Master
- 运行上面的程序则会看到如下日志
- 然而,当我们这时将server停掉,Client会尝试重新连接,并且Client也没有收到任何事件
- 再次启动server,Client再次接收到SyncConnected事件
- 既然Zookeeper Client能够自己尝试尽可能连接上Server,所以对于我们,尽量不要亲自去管理连接。
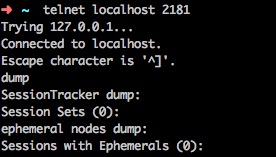
- 我们可以通过telnet观察下Zookeeper状态,可以看到两个Client,一个是之前Master程序,一个就是当前telnet会话。
- 同样,我们还可以通过dump查看一些会话信息,可以看到有一个会话(Master)
- 如果现在我们关掉Master,其实会话并不会马上销毁,而会等到超时。最终才没有了会话
- 当然我们也可以手动关闭连接,而不是等到超时
-
获取领导权(Mastering)
- 现在我们希望Master能够获取到领导权, 之前的文章讲述过,我们需要创建一个临时节点如/master,若该节点已经存在, 说明Master已经存在,否则自己将成为Master。
- 这里,我们创建节点时,指明了节点的权限控制 OPEN_ACL_UNSAFE,这并不安全,但对于例子足以, 在创建节点时,我们捕获了NodeExistsException异常, 表明Master已经存在,而ConnectionLossException异常, 该异常通常由于网络错误,Server崩溃导致,这时Client并不知道请求是否被Server处理,我们不做处理, 而是让Client API尝试重新连接。InterruptedException 异常是由客户端线程导致,可交由外部去处理。接着我们通过getData() 来获取节点数据
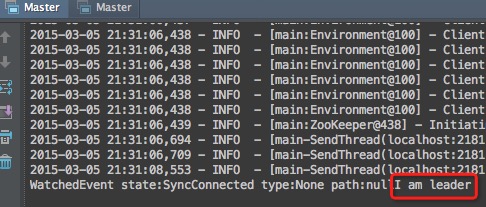
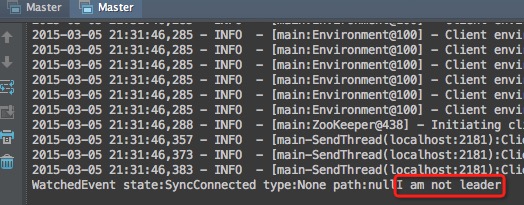
- 我们启动两个进程
- 将看到输出
-
异步获取领导权(Mastering)
- Zookeeper的API都会有一个异步的版本,如创建节点
- 该方法会立即返回,只是将Server请求放入队列中,请求过程放在另一个线程中, 当收到Server响应时,这些响应将在一个专门的回调线程中处理( 因此,你不应该在回调中做太重的操作,或者执行阻塞操作,这会严重影响后续的回调执行), 此方法不会抛出异常,任何请求错误将编码为回调的第一个参数,回调形式为
- 将上面的实现改为异步回调后
- 构建元数据
- Master-Worker架构中,我需要初始化一些元数据,如 /workers, /tasks, /assign
-
注册工作者(Worker)
- 接下来我们会在/workers建立起可用的Worker节点,Worker实现
- 为了保证状态更新的最终一致性,上面Worker实现中需要着重注意的是updateStatus()方法,需要使用 synchronized 和status == this.status判断,否则会出现本地和服务器状态不一致的情况, 比如下面的场景
- 似乎觉得将synchronized放到setStatus()前更合理一些, 会不会出现setStatus("working")后,执行第一条this.status = status之前, CPU时间片切换,Worker就完成了任务,并setStatus("idle"),即 setData("idle")调用在setData("working")之前。
-
任务排队
- 最后的组件则是Client, 我们将把任务创建在/tasks节点下, 并且为每个任务分配唯一的序号。
- 创建任务节点时,如果创建失败,我们就尝试重新创建,但当有多个应用都在创建该任务时, 有可能同一个任务会被创建多次,若要控制某个任务最多创建一次,可以为任务分配唯一的ID。
-
管理员Client
- 我们还需要一个管理员Client来查看系统的状态,通常使用getData()和getChildren()方法。
-
处理状态变化
- 应用需要关注Zookeeper的状态变化,这并不少见,比如 Master-Worker架构中, 备份master需要知道主master是否崩溃, Workers需要知道是否有新的任务分配给自己,在Zookeeper中, 可以通过Watcher机制来实现状态变化监听。
-
一次性触发
- Watches是连接 Znode和事件类型 (Znode数据变化,或节点被删除)的一种一次性触发器。 Watches是同Client的连接会话想关联的,一旦会话过期了, 该会话创建的Watches将被移除。 Watches可以在多个Server之前跨连接, 比如,当Client与集群中的一个Server断开,然后重连到另一个Server,Client将发送未处理的Watches 到该Server,当注册一个Watch时,该Server会检查该Watch 监听的节点是否发生变化,如发生变化,将通知该Client,否则Client就将该Watch注册到新的Server上。
-
一次性触发器会丢失事件吗?
- 答案是肯定的。然而,这种问题值得讨论。 但对于在收到通知 和注册新的Watch 之间丢失事件,我们都可以通过主动读取Zookeeper状态来解决。 比如,Worker收到有新的任务分配通知后, 可以通过getChildren()获取所有分配的任务(即使在收到通知后,又有新任务分配), 再对任务分配节点进行Watch。
-
如何设置Watches
- Zookeeper API所有读操作-- getData(), getChildren(), exists() 都提供Watch的设置, 为了实现watch机制, 我们需要实现Watcher接口, 实现process()方法
- WatchedEvent主要属性
- 事件状态KeeperState分为
- 事件类型EventType分为
-
通用模式
- 在Zookeeper应用中,一个比较通用的代码片段
-
Master-Worker案例
- Master-Worker架构中涉及到几个主要状态变化的地方
- 领导权(Master)改变, 当主Master崩溃时, 备份Master需要立即转变为 主Master, 所以备份Master需要监听 主Master节点删除时, 自己就要尝试创建创建主Master节点。 为了设置监听,我们创建一个叫masterExistsWatcher的监听器
- 下图将更清晰阐述创建master时,可能出现的操作
-
Master监听Worker列表变化
- Master需要监听Worker列表的变化,以便分配新任务或者重新分配未完成的任务。 可以通过getChildren()监听Worker列表变化
-
Master分配新任务
- 当Master一旦发现有新的任务提交时,则会选择一个Worker,并把该任务分配给这个Worker, 所以我们也需要监听任务的变化
-
Worker等待任务分配
- 之前我们已经将Worker注册自己到Zookeeper集群中
- Worker还需要监听分配给自己的新任务
-
客户端监听任务执行结果
- 当Client提交任务后,需要知道任务被执行了及其状态。 当Worker执行一个任务时, 会在/status下创建任务执行状态节点。
-
另一种方式: Multiop
- Multiop并不是Zookeeper的原生设计, 但是在3.4.0时加入到了Zookeeper中。 Multiop可以原子地执行多条Zookeeper操作, 这些操作要么都执行成功,或者都执行失败。通常,我们首先创建操作列表,然后执行 multi,最后获取操作结果列表,如
- 当然也有对应的异步调用方式
- 同样,可以使用Transaction来执行多个操作
- 其中commit()也支持异步调用
- 对于之前Master分配任务时,需要删除 /tasks下的任务节点,并在 /assign下创建任务分配节点, 这里就可以使用multi来完成。
-
使用Watches替代显示的缓存管理器
- 通常我们不愿意Client需要获取Zookeeper数据时,每次都通过 API去读取, 这既费时又消耗服务端资源,最好是在Client做一些数据缓存, 当服务端数据发生变化时,则通知Client作数据更新操作(这也是典型的观察者模式)
-
时序保证
- 当实现Zookeeper应用时,有几个关键的问题需要注意
-
写时序
- Zookeeper状态是跨集群中所有的Server进行复制的,所有Server的状态改变时序应该是保持一致的。 比如集群中一个Server先创建了一个节点/z, 然后删除了一个节点/z',那么集群中的其他Server也会以相同的时序更新状态。
-
读时序
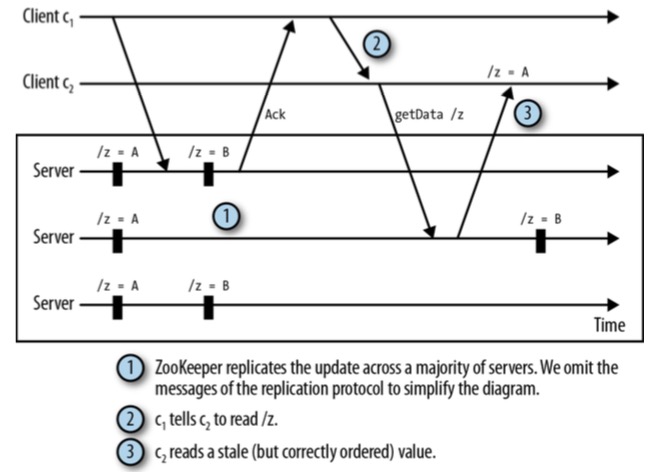
- 在实际中,多个Client可能在不同的时刻看到Zookeeper状态的变化,比如
- 就像如图所示的问题
- 要解决这样的问题,我们应该尽量通过 Watcher来同步状态的更新, 而不是让Client之间直接通信。
-
通知时序
- Zookeeper通知时序是根据状态更新的时序来触发通知的。
-
Watches的羊群效应和可伸缩性
- 如果1000个Client都监听这某个节点,那么当对应的事件被触发时, 将会为这1000个Client发出通知,这无疑会增大延迟操作。 所以对某节点的的某事件监听,最好Client不要太多。
本文将讲述如何使用Zookeeper Client API进行编程, 以在分布式应用中实现协调功能, Zookeeper支持Java和C的API,本文主要使用Java语言。
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.6</version>
</dependency>
/**
* connectString: server列表,如127.0.0.1:2182,127.0.0.1:2183,127.0.0.1:2184
* sessionTimeout: 如果Server超过该时间(毫秒)没能和Client通信,Server将关闭此次会话,通常为5 ~ 10秒。
* watcher: 用于接收Session事件,该事件会在会话建立,关闭或过期时产生,Client也可以用于监控Zookeeper数据变化。
*/
ZooKeeper(String connectString, int sessionTimeout, Watcher watcher)
public interface Watcher {
void process(WatchedEvent event);
}
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import java.io.IOException;
/**
* Author: haolin
* On: 3/4/15
*/
public class Master implements Watcher {
private ZooKeeper zk;
private String connnectHost;
public Master(String connnectHost){
this.connnectHost = connnectHost;
}
public void startZK() throws IOException {
zk = new ZooKeeper(connnectHost, 15000, this);
}
@Override
public void process(WatchedEvent event) {
System.out.print(event);
}
public static void main(String[] args) throws Exception {
String connnectHost = "localhost:2181";
Master m = new Master(connnectHost);
m.startZK();
// wait for a bit
Thread.sleep(60000);
}
}
2015-03-04 23:36:05,661 - INFO - [main:Environment@100] - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT
2015-03-04 23:36:05,664 - INFO - [main:Environment@100] - Client environment:host.name=192.168.0.102
2015-03-04 23:36:05,667 - INFO - [main:Environment@100] - Client environment:java.version=1.7.0_45
2015-03-04 23:36:05,667 - INFO - [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2015-03-04 23:36:05,667 - INFO - [main:Environment@100] - Client environment:java.home=/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre
2015-03-04 23:36:05,667 - INFO - [main:Environment@100] - Client environment:java.class.path=/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/lib/ant-javafx.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/lib/dt.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/lib/javafx-doclet.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/lib/javafx-mx.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/lib/jconsole.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/lib/sa-jdi.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/lib/tools.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/charsets.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/deploy.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/htmlconverter.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/javaws.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/jce.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/jfr.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/jfxrt.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/JObjC.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/jsse.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/management-agent.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/plugin.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/resources.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/rt.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/ext/dnsns.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/ext/localedata.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/ext/sunec.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/ext/sunjce_provider.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/ext/sunpkcs11.jar:/Library/Java/JavaVirtualMachines/jdk1.7.0_45.jdk/Contents/Home/jre/lib/ext/zipfs.jar:/Users/haolin/Learning/langs/java/codes/kb/libraries/zkclient/target/classes:/Users/haolin/Envir/build/maven/m2/repos/org/slf4j/slf4j-api/1.7.1/slf4j-api-1.7.1.jar:/Users/haolin/Envir/build/maven/m2/repos/org/apache/zookeeper/zookeeper/3.4.6/zookeeper-3.4.6.jar:/Users/haolin/Envir/build/maven/m2/repos/org/slf4j/slf4j-log4j12/1.6.1/slf4j-log4j12-1.6.1.jar:/Users/haolin/Envir/build/maven/m2/repos/log4j/log4j/1.2.16/log4j-1.2.16.jar:/Users/haolin/Envir/build/maven/m2/repos/jline/jline/0.9.94/jline-0.9.94.jar:/Users/haolin/Envir/build/maven/m2/repos/io/netty/netty/3.7.0.Final/netty-3.7.0.Final.jar:/Users/haolin/Envir/build/maven/m2/repos/org/apache/curator/curator-recipes/2.1.0-incubating/curator-recipes-2.1.0-incubating.jar:/Users/haolin/Envir/build/maven/m2/repos/org/apache/curator/curator-framework/2.1.0-incubating/curator-framework-2.1.0-incubating.jar:/Users/haolin/Envir/build/maven/m2/repos/org/apache/curator/curator-client/2.1.0-incubating/curator-client-2.1.0-incubating.jar:/Users/haolin/Envir/build/maven/m2/repos/com/google/guava/guava/18.0/guava-18.0.jar:/Users/haolin/Envir/build/maven/m2/repos/org/projectlombok/lombok/1.12.2/lombok-1.12.2.jar:/Users/haolin/Envir/build/maven/m2/repos/org/springframework/spring-core/3.2.6.RELEASE/spring-core-3.2.6.RELEASE.jar:/Users/haolin/Envir/build/maven/m2/repos/commons-logging/commons-logging/1.1.1/commons-logging-1.1.1.jar:/Users/haolin/Envir/build/maven/m2/repos/org/springframework/spring-beans/3.2.6.RELEASE/spring-beans-3.2.6.RELEASE.jar:/Users/haolin/Envir/build/maven/m2/repos/org/springframework/spring-context/3.2.6.RELEASE/spring-context-3.2.6.RELEASE.jar:/Users/haolin/Envir/build/maven/m2/repos/org/springframework/spring-aop/3.2.6.RELEASE/spring-aop-3.2.6.RELEASE.jar:/Users/haolin/Envir/build/maven/m2/repos/org/springframework/spring-expression/3.2.6.RELEASE/spring-expression-3.2.6.RELEASE.jar:/Users/haolin/Envir/build/maven/m2/repos/org/springframework/spring-tx/3.2.6.RELEASE/spring-tx-3.2.6.RELEASE.jar:/Users/haolin/Envir/build/maven/m2/repos/aopalliance/aopalliance/1.0/aopalliance-1.0.jar:/Users/haolin/Envir/build/maven/m2/repos/org/springframework/spring-context-support/3.2.6.RELEASE/spring-context-support-3.2.6.RELEASE.jar:/Users/haolin/Envir/build/maven/m2/repos/org/springframework/spring-jdbc/3.2.6.RELEASE/spring-jdbc-3.2.6.RELEASE.jar:/Applications/IntelliJ IDEA 14 EAP.app/Contents/lib/idea_rt.jar
2015-03-04 23:36:05,668 - INFO - [main:Environment@100] - Client environment:java.library.path=/Users/haolin/Library/Java/Extensions:/Library/Java/Extensions:/Network/Library/Java/Extensions:/System/Library/Java/Extensions:/usr/lib/java:.
2015-03-04 23:36:05,668 - INFO - [main:Environment@100] - Client environment:java.io.tmpdir=/var/folders/c4/1qgb32bj4_j734lwcs9lspsc0000gn/T/
2015-03-04 23:36:05,668 - INFO - [main:Environment@100] - Client environment:java.compiler=<NA>
2015-03-04 23:36:05,668 - INFO - [main:Environment@100] - Client environment:os.name=Mac OS X
2015-03-04 23:36:05,668 - INFO - [main:Environment@100] - Client environment:os.arch=x86_64
2015-03-04 23:36:05,669 - INFO - [main:Environment@100] - Client environment:os.version=10.10.3
2015-03-04 23:36:05,669 - INFO - [main:Environment@100] - Client environment:user.name=haolin
2015-03-04 23:36:05,669 - INFO - [main:Environment@100] - Client environment:user.home=/Users/haolin
2015-03-04 23:36:05,669 - INFO - [main:Environment@100] - Client environment:user.dir=/Users/haolin/Learning/langs/java/codes/kb
2015-03-04 23:36:05,704 - INFO - [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=15000 watcher=org.apache.zookeeper.book.practice.Master@6f85c59c
2015-03-04 23:36:05,965 - INFO - [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2015-03-04 23:36:05,972 - INFO - [main-SendThread(localhost:2181):ClientCnxn$SendThread@852] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2015-03-04 23:36:06,051 - INFO - [main-SendThread(localhost:2181):ClientCnxn$SendThread@1235] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x14bbc76762e0005, negotiated timeout = 15000
WatchedEvent state:SyncConnected type:None path:null
2015-03-04 23:47:55,667 - INFO - [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2015-03-04 23:47:55,669 - WARN - [main-SendThread(localhost:2181):ClientCnxn$SendThread@1102] - Session 0x14bbc76762e0006 for server null, unexpected error, closing socket connection and attempting reconnect
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:735)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:361)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1081)
2015-03-04 23:47:57,771 - INFO - [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2015-03-04 23:47:57,771 - WARN - [main-SendThread(localhost:2181):ClientCnxn$SendThread@1102] - Session 0x14bbc76762e0006 for server null, unexpected error, closing socket connection and attempting reconnect
2015-03-04 23:47:59,847 - INFO - [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authenticate using SASL (unknown error)
2015-03-04 23:47:59,847 - INFO - [main-SendThread(localhost:2181):ClientCnxn$SendThread@852] - Socket connection established to localhost/127.0.0.1:2181, initiating session
2015-03-04 23:47:59,877 - INFO - [main-SendThread(localhost:2181):ClientCnxn$SendThread@1235] - Session establishment complete on server localhost/127.0.0.1:2181, sessionid = 0x14bbc76762e0006, negotiated timeout = 15000
WatchedEvent state:SyncConnected type:None path:null
public void stopZk() throws InterruptedException {
zk.close();
}
// 标识自己
private String serverId = Integer.toHexString(random.nextInt());
// 是否是Leader
private boolean isLeader;
public void runForMaster() throws KeeperException, InterruptedException {
while (true) {
try {
zk.create("/master", serverId.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
// 创建/master节点成功
isLeader = true;
break;
} catch (KeeperException.NodeExistsException e) {
// /master已经存在
isLeader = false;
break;
} catch (KeeperException.ConnectionLossException e) {
}
if (checkMaster()) break;
}
}
/**
* 检查master是否存在
* @return 存在返回true,反之false
*/
private boolean checkMaster() throws InterruptedException{
while (true) {
try {
Stat stat = new Stat();
byte data[] = zk.getData("/master", false, stat);
isLeader = new String(data).equals(serverId);
return true;
} catch (KeeperException.NoNodeException e) {
// 没有master节点,可返回false
return false;
} catch (KeeperException e) {
e.printStackTrace();
}
}
}
/**
* path: 节点路径
* watch: 是否监听节点数据变化
* stat: 节点元数据信息
*/
getData(String path, bool watch, Stat stat)
public static void main(String[] args) throws Exception {
String connnectHost = "localhost:2181";
Master m = new Master(connnectHost);
m.startZK();
m.runForMaster();
if (m.isLeader){
System.out.println("I am leader");
} else {
System.out.println("I am not leader");
}
Thread.sleep(600000);
}
void create(
String path,
byte[] data,
List<ACL> acl,
CreateMode createMode,
AsyncCallback.StringCallback cb, // 回调
Object ctx //用户定义的上下文,回调时会传入
)
/**
* rc: 调用结果,OK或者KeeperException异常码
* path: create传递的path
* ctx: create传递的context
* name: 节点名称,若创建成功将等于path(但对于CreateMode.SEQUENTIAL的节点会加上递增整数)
*/
void processResult(int rc, String path, Object ctx, String name)
private AsyncCallback.StringCallback masterCreateCb = new AsyncCallback.StringCallback() {
@Override
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)){
case CONNECTIONLOSS:
checkMaster();
return;
case OK: // 创建节点成功,成功获取领导权
isLeader = true;
break;
default:
isLeader = false;
}
System.out.println("I'm " + (isLeader ? "" : "not ") + "the leader");
}
};
public void runForMaster(){
zk.create("/master", serverId.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL, masterCreateCb, null);
}
private AsyncCallback.DataCallback masterCheckCb = new AsyncCallback.DataCallback() {
@Override
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
switch(KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
checkMaster();
return;
case NONODE: // 没有master节点存在,则尝试获取领导权
runForMaster();
return;
case NODEEXISTS:
System.out.println("node exists.");
}
}
};
private void checkMaster() {
zk.getData("/master", false, masterCheckCb, null);
}
public void bootstrap() {
// 存放可用的Worker
createParent("/workers", new byte[0]);
// 存放Worker下存放的任务
createParent("/assign", new byte[0]);
// 待执行和新提交的任务
createParent("/tasks", new byte[0]);
createParent("/status", new byte[0]);
}
private void createParent(String path, byte[] data) {
zk.create(path,
data,
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT, // 持久节点
createParentCb,
data); // 将data传给ctx,这样可以在Callback中继续尝试创建节点
}
private AsyncCallback.StringCallback createParentCb = new AsyncCallback.StringCallback() {
@Override
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
createParent(path, (byte[]) ctx); //取出data
break;
case OK:
System.out.println("Parent created");
break;
case NODEEXISTS:
System.out.println("Parent already registered: " + path);
break;
default:
System.err.println("Something went wrong: " + KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
import org.apache.zookeeper.*;
import org.apache.zookeeper.data.Stat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Random;
/**
* Author: haolin
* On: 3/5/15
*/
public class Worker implements Watcher {
private static final Logger LOG = LoggerFactory.getLogger(Worker.class);
private ZooKeeper zk;
private String connnectHost;
private Random random = new Random();
private String serverId = Integer.toHexString(random.nextInt());
private String status;
private String name;
public Worker(String connnectHost) {
this.connnectHost = connnectHost;
}
public void startZK() throws IOException {
zk = new ZooKeeper(connnectHost, 15000, this);
}
@Override
public void process(WatchedEvent event) {
LOG.info(event.toString() + ", " + connnectHost);
}
/**
* 注册自己为Worker
*/
public void register() {
name = "worker-" + serverId;
zk.create(
"/workers/worker-" + name, // worker标识
"Idle".getBytes(), //状态空闲
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL, //临时节点
createWorkerCallback,
null
);
}
private AsyncCallback.StringCallback createWorkerCallback = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
register();
break;
case OK:
LOG.info("Registered successfully: " + serverId);
break;
case NODEEXISTS:
LOG.warn("Already registered: " + serverId);
break;
default:
LOG.error("Something went wrong: "
+ KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
private AsyncCallback.StatCallback statusUpdateCallback = new AsyncCallback.StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
switch(KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
updateStatus((String)ctx);
return;
}
}
};
synchronized private void updateStatus(String status) {
if (status == this.status) {
zk.setData(
"/workers/" + name,
status.getBytes(),
-1, // -1将不会检查版本
statusUpdateCallback,
status
);
}
}
/**
* 设置状态
* @param status 新状态
*/
public void setStatus(String status) {
this.status = status;
updateStatus(status);
}
public static void main(String args[]) throws Exception {
Worker w = new Worker("localhost:2181");
w.startZK();
w.register();
Thread.sleep(60000);
}
}
1. Worker开始执行任务task-1,因此调用
setStatus("working")(即this.status = "working")。
2. Client API发起setData()调用,但是此时发生网络错误。
3. 于是Client API认为与Server失去连接,但在调用statusUpdateCallback回调之前,
Worker完成了任务,变得空闲。
4. 因此调用setStatus("idle")(即this.status = "idle")。
5. 然而,现在Client开始处理第二步中产生的网络错误回调statusUpdateCallback,
若不判断status == this.status,Worker的状态将被设置为
"working",这就会造成Client和Server状态不一致。
public class Client implements Watcher {
private ZooKeeper zk;
private String connnectHost;
public Client(String connnectHost) { this.connnectHost = connnectHost; }
public void startZK() throws Exception {
zk = new ZooKeeper(connnectHost, 15000, this);
}
public String queueCommand(String command) throws Exception {
String name = null;
while (true) {
try {
// 新节点名称
name = zk.create("/tasks/task-",
command.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL); // 持久临时节点
return name;
} catch (KeeperException.NodeExistsException e) {
throw new Exception(name + " already appears to be running");
} catch (KeeperException.ConnectionLossException e) {
}
}
}
@Override
public void process(WatchedEvent event) {
}
public static void main(String args[]) throws Exception {
Client c = new Client("localhost:2181");
c.startZK();
String name = c.queueCommand("some cmd");
System.out.println("Created " + name);
}
}
import org.apache.zookeeper.KeeperException;
import org.apache.zookeeper.WatchedEvent;
import org.apache.zookeeper.Watcher;
import org.apache.zookeeper.ZooKeeper;
import org.apache.zookeeper.data.Stat;
import java.util.Date;
/**
* Author: haolin
* On: 3/9/15
*/
public class AdminClient implements Watcher {
private ZooKeeper zk;
private String connnectHost;
public AdminClient(String connnectHost) { this.connnectHost = connnectHost; }
public void start() throws Exception {
zk = new ZooKeeper(connnectHost, 15000, this);
}
public void listState() throws KeeperException, InterruptedException {
try {
Stat stat = new Stat();
// master状态
byte masterData[] = zk.getData("/master", false, stat);
Date startDate = new Date(stat.getCtime()); //master创建时间
System.out.println("Master: " + new String(masterData) + " since " + startDate);
} catch (KeeperException.NoNodeException e) {
System.out.println("No Master");
}
// worker状态
System.out.println("Workers:");
for (String w: zk.getChildren("/workers", false)) {
byte data[] = zk.getData("/workers/" + w, false, null);
String state = new String(data);
System.out.println("\t" + w + ": " + state);
}
// 任务分配状态
System.out.println("Tasks:");
for (String t: zk.getChildren("/assign", false)) {
System.out.println("\t" + t);
}
}
@Override
public void process(WatchedEvent event) {
}
public static void main(String args[]) throws Exception {
AdminClient c = new AdminClient("localhost:2181");
c.start();
c.listState();
}
}
public void process(WatchedEvent event);
public class WatchedEvent {
// 事件通知状态
final private KeeperState keeperState;
// 事件类型
final private EventType eventType;
// 节点路径
private String path;
...
}
public enum KeeperState {
// Client没有连接到任何集群中的Server
Disconnected (0),
// Client与集群中的某个Server连接
SyncConnected (3),
// 认证失败
AuthFailed (4),
// Client连接到一个只读Server,只能执行读操作
ConnectedReadOnly (5),
// 通知Client已经通过了Sasl认证
SaslAuthenticated(6),
// Client会话已经过期
Expired (-112);
}
public enum EventType {
// Zookeeper会话状态改变时的事件
None (-1),
// 节点创建,通过exists调用
NodeCreated (1),
// 节点删除,通过exists或getData调用
NodeDeleted (2),
// 节点数据改变,通过exists或getData调用
NodeDataChanged (3),
// 节点的子节点创建或删除,通过getChildren调用
NodeChildrenChanged (4),
// 节点数据监听器被删除,通过exists或getData调用
DataWatchRemoved (5),
// 节点的子节点监听器被删除,通过getChildren调用
ChildWatchRemoved (6);
}
// 1. 异步调用
zk.exists("/myZnode", myWatcher,existsCallback, null);
// 2. 实现回调对象
StatCallback existsCallback = new StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
// Process the result of the exists call
}
};
// 3. 如果操作需要设置监听,则实现一个监听类
Watcher myWatcher = new Watcher() {
public void process(WatchedEvent e) {
// Process the watch event
}
}
1. 领导权(Master)改变
2. Master监听Worker列表改变
3. Master监听新的任务提交
4. Worker监听任务分配
5. Client等待任务执行结果
// 选举自己为master
public void runForMaster(){
zk.create("/master", serverId.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL, masterCreateCb, null);
}
private AsyncCallback.StringCallback masterCreateCb = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 检查Master状态
checkMaster();
break;
case OK:
// 自己成为了Master
state = MasterStates.ELECTED;
// 获取领导权
takeLeadership();
break;
case NODEEXISTS:
// Master已经存在,自己没被选上
state = MasterStates.NOTELECTED;
// 监听master存在性
masterExists();
break;
default:
state = MasterStates.NOTELECTED;
LOG.error("Something went wrong when running for master.");
}
}
};
private MasterStates state;
// Master状态
private enum MasterStates {
RUNNING,
ELECTED,
NOTELECTED
}
/**
* 监听master存在性
*/
private void masterExists() {
zk.exists("/master",
masterExistsWatcher, masterExistsCallback, null);
}
private AsyncCallback.StatCallback masterExistsCallback = new AsyncCallback.StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接失败,继续监听master存在性
masterExists();
break;
case OK:
// master节点已不存在(master节点有可能在执行完masterCreateCb和exists之间被删除了
if(stat == null) {
state = MasterStates.RUNNING;
// 选举自己为Master
runForMaster();
}
break;
default:
// 检查Master状态
checkMaster();
break;
}
}
};
// Master存在性监听器
private Watcher masterExistsWatcher = new Watcher() {
public void process(WatchedEvent e) {
// 若master节点已被删除
if(e.getType() == Event.EventType.NodeDeleted) {
assert "/master".equals(e.getPath());
runForMaster();
}
}
};
// 获取领导权
private void takeLeadership() {
// ...
}
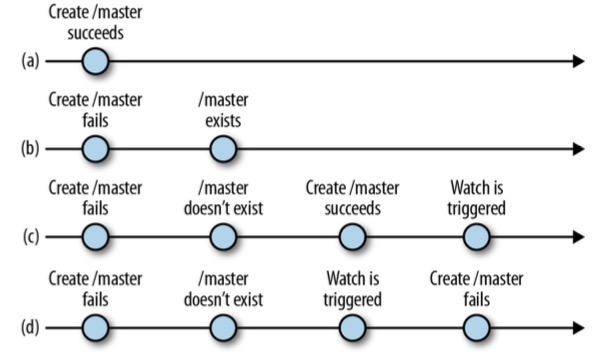
(a):成功创建主Master,不许做其他事情。
(b):如果由于Master存在而创建失败,将对master节点进行监听。
(c):在
runForMaster()和正在执行exists()
之间,master节点有可能被删除,这种情况下,回调masterCreateCb
就可能认为master节点仍然存在,于是仅仅调用
masterExists()来监听master节点的存在性,
进而会继续在回调masterExistsCallback中,
执行runForMaster()尝试创建master节点,
若创建master节点成功,masterExistsWatcher将得到通知,
但这并没有什么意义,因为是自己创建master造成了变化。
(d):若(c)中创建master节点失败,
我们又继续监听Master的存在性。
private Watcher workersChangeWatcher = new Watcher() {
public void process(WatchedEvent e) {
// Children发生变化,则重新获取最新的Worker列表
if(e.getType() == Event.EventType.NodeChildrenChanged) {
assert "/workers".equals(e.getPath());
getWorkers();
}
}
};
private AsyncCallback.ChildrenCallback workersGetChildrenCallback = new AsyncCallback.ChildrenCallback() {
public void processResult(int rc, String path, Object ctx, List<String> children) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 发生连接错误,尝试重新获取Worker列表
getWorkers();
break;
case OK:
LOG.info("Succesfully got a list of workers: " + children.size() + " workers");
// 重分配崩溃的Worker的任务给其他Worker
reassignAndSet(children);
break;
default:
LOG.error("getChildren failed", KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
/**
* 监听worker列表
*/
private void getWorkers() {
zk.getChildren("/workers", workersChangeWatcher, workersGetChildrenCallback, null);
}
/**
* 缓存最新的Worker列表
*/
private ChildrenCache workersCache;
/**
* 重分配崩溃的Worker的任务给其他Worker
*/
private void reassignAndSet(List<String> children) {
List<String> toProcess = null;
if(workersCache == null) {
// 初始化缓存
workersCache = new ChildrenCache(children);
} else {
LOG.info( "Removing and setting" );
// 检查某些被删除的Worker
toProcess = workersCache.removedAndSet(children);
}
if(toProcess != null) {
for(String worker : toProcess) {
// 重新分配删除的Worker的任务
getAbsentWorkerTasks(worker);
}
}
}
private void getAbsentWorkerTasks(String worker) {
// ...
}
/**
* 任务列表变化监听
*/
private Watcher tasksChangeWatcher = new Watcher() {
public void process(WatchedEvent e) {
if(e.getType() == Event.EventType.NodeChildrenChanged) {
assert "/tasks".equals( e.getPath() );
getTasks();
}
}
};
AsyncCallback.ChildrenCallback tasksGetChildrenCallback = new AsyncCallback.ChildrenCallback() {
public void processResult(int rc, String path, Object ctx, List<String> children) {
switch(KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接错误,尝试重新获取任务列表
getTasks();
break;
case OK:
if(children != null) {
// 分配新任务
assignTasks(children);
}
break;
default:
LOG.error("getChildren failed.", KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
private void assignTasks(List<String> tasks) {
for(String task : tasks) {
getTaskData(task);
}
}
// 获取任务数据
private void getTaskData(String task) {
zk.getData("/tasks/" + task,
false, taskDataCallback, task);
}
private AsyncCallback.DataCallback taskDataCallback = new AsyncCallback.DataCallback(){
@Override
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
switch(KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接断开,再次尝试获取任务数据
getTaskData((String) ctx);
break;
case OK:
// 选择一个Worker
int worker = random.nextInt(workersCache.getList().size());
String designatedWorker = workersCache.getList().get(worker);
String assignmentPath = "/assign/" + designatedWorker + "/" + ctx;
// 创建任务分配
createAssignment(assignmentPath, data);
break;
default:
LOG.error("Error when trying to get task data.", KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
/**
* 创建任务分配
*/
private void createAssignment(String path, byte[] data) {
zk.create(path,
data, ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT,
assignTaskCallback,
data);
}
private AsyncCallback.StringCallback assignTaskCallback = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch(KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接断开,尝试重新创建任务分配
createAssignment(path, (byte[]) ctx);
break;
case OK:
LOG.info("Task assigned correctly: " + name);
// 分配完成后,删除任务
deleteTask(name.substring(name.lastIndexOf("/") + 1 ));
break;
case NODEEXISTS:
LOG.warn("Task already assigned");
break;
default:
LOG.error("Error when trying to assign task.", KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
/**
* 删除任务
* @param name
*/
private void deleteTask(String name) {
zk.delete("/tasks/" + name, -1, taskDeleteCallback, null);
}
private AsyncCallback.VoidCallback taskDeleteCallback = new AsyncCallback.VoidCallback(){
public void processResult(int rc, String path, Object ctx){
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接断开,尝试再次删除任务
deleteTask(path);
break;
case OK:
LOG.info("Successfully deleted " + path);
break;
case NONODE:
LOG.info("Task has been deleted already");
break;
default:
LOG.error("Something went wrong here, " + KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
/**
* 获取任务列表
*/
public void getTasks() {
zk.getChildren("/tasks", tasksChangeWatcher, tasksGetChildrenCallback, null);
}
public void register() {
name = "worker-" + serverId;
zk.create(
"/workers/worker-" + name, // worker标识
"Idle".getBytes(), //状态空闲
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL, //临时节点
createWorkerCallback,
null
);
}
private AsyncCallback.StringCallback createWorkerCallback = new AsyncCallback.StringCallback() {
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
register();
break;
case OK:
LOG.info("Registered successfully: " + serverId);
break;
case NODEEXISTS:
LOG.warn("Already registered: " + serverId);
break;
default:
LOG.error("Something went wrong: "
+ KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
/**
* 新任务监听器
*/
private Watcher newTaskWatcher = new Watcher() {
public void process(WatchedEvent e) {
if(e.getType() == Event.EventType.NodeChildrenChanged) {
assert new String("/assign/worker-"+ serverId).equals( e.getPath() );
getTasks();
}
}
};
/**
* 获取Worker下的任务列表
*/
public void getTasks() {
zk.getChildren("/assign/worker-" + serverId,
newTaskWatcher, tasksGetChildrenCallback, null);
}
/**
* 通过线程池来执行任务
*/
private ThreadPoolExecutor taskExecutor = new ThreadPoolExecutor(
1, 1, 1000L, TimeUnit.MILLISECONDS, new ArrayBlockingQueue<Runnable>(200));
/**
* 分配给Worker的任务
*/
protected ChildrenCache assignedTasksCache = new ChildrenCache();
private AsyncCallback.ChildrenCallback tasksGetChildrenCallback = new AsyncCallback.ChildrenCallback() {
@Override
public void processResult(int rc, String path, Object ctx, List<String> children) {
switch(KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 尝试重新获取分配给自己的任务
getTasks();
break;
case OK:
if(children != null) {
// 通过线程池获取任务数据,避免回调阻塞
taskExecutor.execute(new Runnable() {
List<String> children;
DataCallback cb;
public Runnable init (List<String> children, DataCallback cb) {
this.children = children;
this.cb = cb;
return this;
}
public void run() {
if(children == null) {
return;
}
LOG.info("Looping into tasks");
setStatus("Working");
for(String task : children){
LOG.trace("New task: {}", task);
// 获取对应任务的数据
zk.getData(
"/assign/worker-" + serverId + "/" + task,
false,
cb,
task
);
}
}
}.init(assignedTasksCache.addedAndSet(children), taskDataCallback));
}
break;
default:
System.out.println("getChildren failed: " +
KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
AsyncCallback.DataCallback taskDataCallback = new AsyncCallback.DataCallback() {
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat){
switch(KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接错误,再次尝试获取数据
zk.getData(path, false, taskDataCallback, null);
break;
case OK:
// 在线程池中执行任务,避免回调阻塞
taskExecutor.execute( new Runnable() {
byte[] data;
Object ctx;
public Runnable init(byte[] data, Object ctx) {
this.data = data;
this.ctx = ctx;
return this;
}
public void run() {
LOG.info("Executing your task: " + new String(data));
// 创建任务执行状态为dome
zk.create("/status/" + (String) ctx, "done".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT, taskStatusCreateCallback, null);
// 删除Worker下的任务分配
zk.delete("/assign/worker-" + serverId + "/" + (String) ctx,
-1, taskVoidCallback, null);
}
}.init(data, ctx));
break;
default:
LOG.error("Failed to get task data: ", KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
AsyncCallback.VoidCallback taskVoidCallback = new AsyncCallback.VoidCallback(){
public void processResult(int rc, String path, Object rtx){
switch(KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
break;
case OK:
LOG.info("Task correctly deleted: " + path);
break;
default:
LOG.error("Failed to delete task data" + KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
private void submitTask(String task, TaskObject taskCtx) {
taskCtx.setTask(task);
zk.create(
"/tasks/task-",
task.getBytes(),
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT_SEQUENTIAL,
createTaskCallback,
taskCtx
);
}
private AsyncCallback.StringCallback createTaskCallback = new AsyncCallback.StringCallback(){
@Override
public void processResult(int rc, String path, Object ctx, String name) {
switch (KeeperException.Code.get(rc)){
case CONNECTIONLOSS:
// 连接失败,再次尝试提交任务
submitTask(((TaskObject)ctx).getTask(), (TaskObject) ctx);
break;
case OK:
LOG.info("My created task name: " + name);
((TaskObject) ctx).setTaskName(name);
// 监听任务状态
watchStatus("/status/" + name.replace("/tasks/", ""), ctx);
break;
default:
break;
}
}
};
/**
* 关联任务节点路径和任务对象
*/
private ConcurrentHashMap<String, Object> ctxMap = new ConcurrentHashMap<String, Object>();
/**
* 监听任务执行状态
* @param path
* @param ctx
*/
private void watchTaskStatus(String path, Object ctx){
ctxMap.put(path, ctx);
zk.exists(
path,
taskStatusWatcher,
taskExistsCallback,
ctx
);
}
private AsyncCallback.StatCallback taskExistsCallback = new AsyncCallback.StatCallback() {
public void processResult(int rc, String path, Object ctx, Stat stat) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接失败,尝试重新监听任务状态
watchTaskStatus(path, ctx);
break;
case OK:
if (stat != null) {
// 获取任务数据
zk.getData(path, false, getDataCallback, null);
}
break;
case NONODE:
break;
default:
LOG.error("Something went wrong when " +
"checking if the status node exists: " + KeeperException.create(KeeperException.Code.get(rc), path));
break;
}
}
};
/**
* 任务状态监听
*/
private Watcher taskStatusWatcher = new Watcher() {
@Override
public void process(WatchedEvent e) {
// 任务开始处于被执行状态
if(e.getType() == Event.EventType.NodeCreated) {
assert e.getPath().contains("/status/task-");
zk.getData(e.getPath(),false,
getDataCallback, ctxMap.get(e.getPath()));
}
}
};
/**
* 获取任务节点数据回调
*/
AsyncCallback.DataCallback getDataCallback = new AsyncCallback.DataCallback(){
public void processResult(int rc, String path, Object ctx, byte[] data, Stat stat) {
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 连接失败,尝试重新获取任务数据
zk.getData(path, false, getDataCallback, ctxMap.get(path));
return;
case OK:
String taskResult = new String(data);
LOG.info("Task " + path + ", " + taskResult);
assert(ctx != null);
// 本地设置任务已完成
((TaskObject) ctx).setStatus(taskResult.contains("done"));
// 删除任务状态节点
zk.delete(path, -1, taskDeleteCallback, null);
ctxMap.remove(path);
break;
case NONODE:
LOG.warn("Status node is gone!");
return;
default:
LOG.error("Something went wrong here, " +
KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
/**
* 删除任务状态节点回调
*/
AsyncCallback.VoidCallback taskDeleteCallback = new AsyncCallback.VoidCallback(){
public void processResult(int rc, String path, Object ctx){
switch (KeeperException.Code.get(rc)) {
case CONNECTIONLOSS:
// 删除失败,尝试重新删除任务状态节点
zk.delete(path, -1, taskDeleteCallback, null);
ctxMap.remove(path);
break;
case OK:
LOG.info("Successfully deleted " + path);
break;
default:
LOG.error("Something went wrong here, " +
KeeperException.create(KeeperException.Code.get(rc), path));
}
}
};
public class TaskObject {
private static final Logger LOG = LoggerFactory.getLogger(TaskObject.class);
private String task;
private String taskName;
private boolean done = false;
private boolean successful = false;
private CountDownLatch latch = new CountDownLatch(1);
String getTask() {
return task;
}
void setTask(String task) {
this.task = task;
}
void setTaskName(String name) {
this.taskName = name;
}
String getTaskName() {
return taskName;
}
public void setStatus(boolean status) {
successful = status;
done = true;
latch.countDown();
}
public void waitUntilDone() {
try {
latch.await();
} catch (InterruptedException e) {
LOG.warn("InterruptedException while waiting for task to get done");
}
}
public synchronized boolean isDone() {
return done;
}
public synchronized boolean isSuccessful() {
return successful;
}
}
// 删除节点操作
Op deleteZnode(String z) {
return Op.delete(z, -1);
}
List<OpResult> results = zk.multi(
Arrays.asList(deleteZnode("/a/b"),deleteZnode("/a")
);
public void multi(Iterable<Op> ops, MultiCallback cb, Object ctx);
Transaction t = new Transaction();
t.delete("/a/b", -1);
t.delete("/a", -1);
List<OpResult> results = t.commit();
public void commit(MultiCallback cb, Object ctx);
1. Client c1更新了节点/z的数据,并收到了确认信息。
2. Client c1直接通过TCP发送信息给Client c2,通知c2节点/z状态发生了改变。
3. Client c2读取节点/z的状态,但是确观察到c1更新之前的状态