
-
InnoDB存储引擎简介
-
使用InnoDB表的好处
-
有关InnoDB表的最佳实践
-
检查数据库是否支持InnoDB存储模型
-
InnoDB与ACID模型
-
InnoDB存储引擎如何与ACID模型相互作用
-
Atomicity(原子性)
-
Consistency(一致性)
-
Isolation(隔离性)
-
Durability(持久性)
-
InnoDB的多版本控制
-
多版本与二级索引
-
总结
-
参考文献
对于MySQL,大家应该不会陌生,对于数据库,其最重要核心的功能就是如何存储,检索数据库,这将取决于其使用的存储引擎,在MySQL中,有一些可选的存储引擎,如InnoDB,MyISAM,MEMORY等,其中使用最为广泛的则是InnoDB,因为无论从高可用和高性能等方面,其能满足大多数的应用场景,本文将对MySQL的InnoDB存储引擎作一些基本简介,将基于MySQL 5.7。
InnoDB作为比较通用的存储引擎,其在高可用和高性能两方面作了较好的平衡,因此也作为了MySQL的默认存储引擎。相较于其他存储引擎,InnoDB有几点关键的优势:
下表是InnoDB的一些特性:
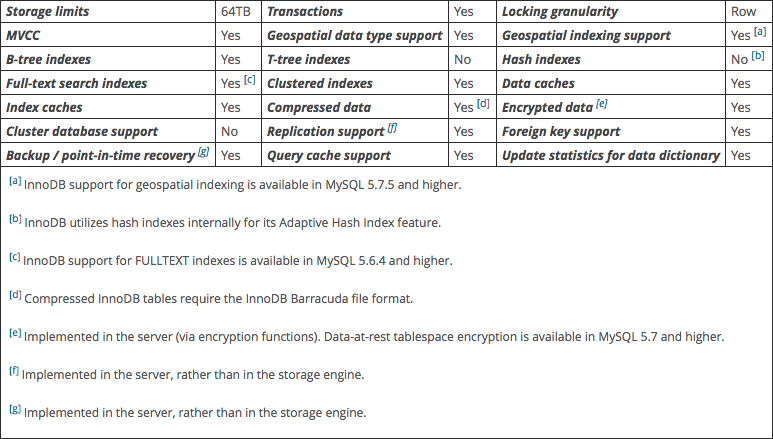
相较于MyISAM等存储类型的表,InnoDB表具有以下一些优势:
以下是使用InnoDB表的一些最佳实践:
可以通过SHOW ENGINGES来检查当前数据库是否支持InnoDB:
mysql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
或者直接查询INFORMATION_SCHEMA库的ENGINES表:
mysql> use INFORMATION_SCHEMA;
mysql> SELECT * FROM ENGINES;
# 同上
若ENGINES中没有InnoDB,则可能需要重新安装支持InnoDB的MySQL版本;若InnoDB没有开启,在启动Mysql时,去掉skip-innodb相关的选项(这些选项在MySQL 5.7.5及之后已经无效)。另外,可以通过--default-storage-engine=InnoDB指定InnoDB为默认的存储引擎。
若想禁用InnoDB存储引擎,可以在启动MySQL时使用--innodb=OFF参数。
ACID模型作为数据库设计的重要原则,其强调了对业务数据和关键应用的可靠性方面的重要性。MySQL包含了一些组件,如InnoDB存储引擎,实现了ACID模型,这样可以保证数据不会损坏,或者不会因为软件崩溃和硬件故障导致数据异常。当你的应用需要依赖ACID特性时,就不再需要再作一致性校验和故障恢复等。如果你的应用已经从程序上保证了一定的一致性,或者具有高可靠的意见,又或应用允许一定的数据不一致,丢失等,那么你可以调整MySQL的ACID可靠性配置,以获取更好的性能或吞吐量。
InnoDB中原子性主要体现在事务:
InnoDB中一致性主要体现在当服务器崩溃时,能保护数据:
InnoDB中隔离性主要体现在事务,特别是隔离级别,与MySQL相关的特性有:
InnoDB中持久性主要体现在特性硬件上的影响,由于涉及到CPU,网络和存储设备等多个因素,若要提供出具体的配置策略方案,会比较困难。与持久性相关的MySQL特性大致有:
InnoDB属于多版本控制的存储引擎:为了支持如并发或回滚等事务特性,InnoDB会保存变更数据的多个旧版本,这些数据被保存在一个叫Rollback Segment的数据结构中(类似于Oracle),当事务回滚时,InnoDB将利用这些信息作一些必要的撤销操作,这些信息也用来作一些一致性读相关的操作。
本质上,InnoDB内部保存记录时,会额外加上三个字段:
| 字段名称 | 字段长度 | 描述 |
|---|---|---|
| DB_TRX_ID | 6(Byte) | 表示记录最后被插入或更新时对应的事务ID。对于删除操作,会被记作更新操作,并且其中一位用于标记为删除操作; |
| DB_ROLL_PTR | 7(Byte) | 回滚指针。该指针指向回滚段(rollback segment)中的撤销日志记录(Undo Log Record),若某一行记录被更新了,该日志中将添加用于恢复记录被更新前的内容; |
| DB_ROW_ID | 6(Byte) | 一个单调递增的行ID。 |
位于回滚段中的撤销日志会被分为插入撤销日志和更新撤销日志。插入撤销日志主要用于事务回滚,一旦事务提交就可以被丢弃。更新撤销日志用于一致性读操作,仅能在没有事务存在时被删除,此时InnoDB会为一致性读操作创建一份来自更新撤销日志的快照。因此,你需要适当提交事务,包括一致性读操作,否则,InnoDB将不能删除掉相关的更新撤销日志,使得回滚文件太大。通常,撤销日志的大小会比对应插入或更新的数据库记录都小,这样就可以评估回滚文件所需要占用的磁盘大小。
在InnoDB的多版本模式中,当执行完DELETE语句后,数据库记录并不会立即物理删除,而只有当对应记录的更新撤销日志删除后,才会物理删除该记录,该操作叫purge(清除)
InnoDB的多版本并发控制(MVCC)在处理二级索引时,与聚簇索引有所不同。聚簇索引中的记录可以直接更新,其隐藏的系统列指向撤销日志中的记录。与聚簇索引不同,二级索引记录不能直接更新,且不包含隐藏的系统列。
当更新二级索引列时,旧的二级索引记录将被标记为删除,然后插入新记录,最后清除标记为删除的二级索引记录。当二级索引记录被标记为删除,或二级索引页被新的事务更新时,InnoDB将在聚簇索引记录中查询对应的数据库记录。在聚簇索引记录中,将校验记录的DB_TRX_ID,如果在读事务启动后修改了记录,则从撤销日志中检索正确的记录版本。
然而,如果启用索引条件下推(ICP)优化,并且可以仅使用索引中的字段来评估WHERE条件的部分,则MySQL服务器仍将WHERE条件的这部分下推到存储引擎使用索引。 如果没有找到匹配的记录,则避免查找聚集索引。 如果找到匹配的记录(即使在删除标记的记录中),InnoDB也会在聚集索引中查找记录。
以上,则是InnoDB相关的基础简介,主要介绍了其特性,优势,及相关实践等。

