
-
性能指标
-
垃圾收集(GC)中的性能指标
-
延迟时间(Latency)
-
吞吐量(Throughput)
-
容量(Capacity)
-
调优案例
-
代码示例
-
优化延迟时间(Latency)
-
吞吐量(Throughput)
-
容量(Capacity)
-
常见的GC调优工具
-
JMX API
-
JVisualVM
-
jstat
-
GC logs
-
hprof
-
一些典型的GC调优案例
-
分配率过高
-
如何测试分配率
-
对象过早晋升
-
Weak,Soft及Phantom引用
-
总结
-
参考文献
随着Java应用地运行,可能会出现一系列性能问题,如系统吞吐量低,系统延迟高等,这些通常会直接影响用户体验,造成用户流失,严重时,系统将会崩溃,为了避免这样的情况发生在线上,通常会在上线系统前作一些指标测试,如吞吐量,延迟等,当然影响这些指标的因素可能会有很多,如计算复杂度,网络问题,但本文将仅从JVM的垃圾收集调优讲起。
通常,在系统调优中,都会涉及几个指标:
| 指标项 | 描述 |
|---|---|
| 延迟时间(Latency) | 延迟时间指的是完成一个操作所需要的时间。 |
| 吞吐量(Throughput) | 吞吐量指的是单位时间内完成了多少次某项操作。 |
| 容量(Capacity) | 容量指的是完成某项操作使用的资源容量。 |
在日常开发中,经常会有这样的需求,要求用户的某个操作,必须在1秒内得到响应,这个时候首先需要确认的是,垃圾收集(GC)造成的暂停时间是否占用得过多,若GC造成的暂停时间仅几十毫秒,则可以尝试从其他层面去作优化处理,比如外部数据源,锁争用等问题,事实证明,这些问题可能会比GC问题出现得更多。假设,现在的性能需求是:90%的操作的响应时间必须小于1000ms,没有任何操作的响应时间大于10000ms,并假设GC停顿占用的时间不能超过10%,即90%的GC暂停时间不能超过100ms,没有一次GC的暂停时间超过1000ms。如下面的GC日志:
[Full GC (Ergonomics) [PSYoungGen: 93677K- >70109K(254976K)] [ParOldGen: 499597K->511230K(761856K)] 593275K->581339K(1016832K), [Metaspace: 2936K->2936K(1056768K)], 0.0713174 secs] [Times: user=0.21 sys=0.02, real=0.07 secs
本次GC的暂停时间为0.0713174 secs,尽管耗费的总CPU时间为0.21 secs,但我们更专注的是应用暂停时间,由于采用的是并行垃圾收集器,真实耗时仅0.07 secs,满足了延迟性能需求。
与延迟时间不同,吞吐量更关注垃圾收集(GC)在应用运行时所占用的时间比。假设,现在性能的需求是:系统每分钟处理1000次事务,要求GC占用的总时间不能超过10%,即6s。如上面的GC日志,一次GC耗时0.07 secs,若一分钟内的GC次数 * 70ms不超过6000ms,也满足了吞吐量性能需求。
容量要求对运行时环境作出更改(如调整内存大小,限制成本等),以达到延迟和吞吐量的性能需求。
public class GCTuningTest implements Runnable {
private static ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2);
private Deque<byte[]> deque;
private int objectSize;
private int queueSize;
public GCTuningTest(int objectSize, int ttl) {
this.deque = new ArrayDeque<>();
this.objectSize = objectSize;
this.queueSize = ttl * 1000;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
deque.add(new byte[objectSize]);
if (deque.size() > queueSize) {
deque.poll();
}
}
}
public static void main(String[] args) throws InterruptedException {
// 每隔100ms,申请大小为0.2M的对象
executorService.scheduleAtFixedRate(new GCTuningTest(200 * 1024 * 1024 / 1000, 5), 0, 100, TimeUnit.MILLISECONDS);
// 每隔100ms,申请大小为0.05M的对象
executorService.scheduleAtFixedRate(new GCTuningTest(50 * 1024 * 1024 / 1000, 120), 0, 100, TimeUnit.MILLISECONDS);
TimeUnit.MINUTES.sleep(10);
executorService.shutdownNow();
}
}
通过以下VM参数,可看出类似的GC日志信息:
-Xms2g -Xmx2g -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
2016-04-14T20:26:13.202-0800: 2.040: [GC [PSYoungGen: 525312K->87030K(612352K)] 525312K->489822K(2010624K), 0.2176960 secs] [Times: user=0.19 sys=0.55, real=0.22 secs]
2016-04-14T20:26:15.200-0800: 4.038: [GC [PSYoungGen: 612183K->87023K(612352K)] 1014975K->1006816K(2010624K), 0.3084190 secs] [Times: user=0.24 sys=0.63, real=0.30 secs]
2016-04-14T20:26:15.508-0800: 4.346: [Full GC [PSYoungGen: 87023K->0K(612352K)] [ParOldGen: 919793K->1006703K(1398272K)] 1006816K->1006703K(2010624K) [PSPermGen: 3183K->3181K(21504K)], 0.2024470 secs] [Times: user=0.09 sys=0.08, real=0.21 secs]
上面的GC日志表明,使用的是并行垃圾收集器(Parallel Garbage Collector),并且从日志可以看出,Young GC和Full GC耗时都比较长,达到了100ms级别,下面将从不同维度进行一些简单调优。
假如,现在需求是,大部分GC的暂停时间必须小于100ms,最简单直接的做法,尝试将默认是并行垃圾收集器改为CMS垃圾收集器,即:
-Xms2g -Xmx2g -XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps
2016-04-14T20:34:29.573-0800: 40.386: [GC2016-04-14T20:34:29.573-0800: 40.386: [ParNew: 306602K->306602K(306688K), 0.0000340 secs]2016-04-14T20:34:29.573-0800: 40.386: [CMS: 1756394K->1756394K(1756416K), 0.0794200 secs] 2062997K->2062887K(2063104K), [CMS Perm : 3183K->3183K(21248K)], 0.0795220 secs] [Times: user=0.08 sys=0.00, real=0.08 secs]
2016-04-14T20:34:29.652-0800: 40.465: [GC [1 CMS-initial-mark: 1756394K(1756416K)] 2063041K(2063104K), 0.0007970 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2016-04-14T20:34:29.653-0800: 40.466: [CMS-concurrent-mark-start]
2016-04-14T20:34:29.653-0800: 40.467: [Full GC2016-04-14T20:34:29.653-0800: 40.467: [CMS2016-04-14T20:34:29.667-0800: 40.480: [CMS-concurrent-mark: 0.014/0.014 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
(concurrent mode failure): 1756394K->1756394K(1756416K), 0.0394660 secs] 2063041K->2063041K(2063104K), [CMS Perm : 3183K->3183K(21248K)], 0.0395070 secs] [Times: user=0.04 sys=0.00, real=0.04 secs]
2016-04-14T20:34:29.693-0800: 40.506: [Full GC2016-04-14T20:34:29.693-0800: 40.506: [CMS: 1756394K->1756394K(1756416K), 0.0256660 secs] 2063041K->2063041K(2063104K), [CMS Perm : 3183K->3183K(21248K)], 0.0257160 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
2016-04-14T20:34:31.720-0800: 42.534: [GC [1 CMS-initial-mark: 1756394K(1756416K)] 2063041K(2063104K), 0.0010680 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2016-04-14T20:34:31.722-0800: 42.535: [CMS-concurrent-mark-start]
2016-04-14T20:34:31.736-0800: 42.549: [CMS-concurrent-mark: 0.014/0.014 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
2016-04-14T20:34:31.736-0800: 42.549: [CMS-concurrent-preclean-start]
2016-04-14T20:34:31.748-0800: 42.562: [CMS-concurrent-preclean: 0.012/0.012 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
2016-04-14T20:34:31.749-0800: 42.562: [CMS-concurrent-abortable-preclean-start]
2016-04-14T20:34:31.749-0800: 42.562: [CMS-concurrent-abortable-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2016-04-14T20:34:31.749-0800: 42.562: [GC[YG occupancy: 306646 K (306688 K)]2016-04-14T20:34:31.749-0800: 42.562: [Rescan (parallel) , 0.0022080 secs]2016-04-14T20:34:31.751-0800: 42.564: [weak refs processing, 0.0000270 secs]2016-04-14T20:34:31.751-0800: 42.564: [scrub string table, 0.0001950 secs] [1 CMS-remark: 1756394K(1756416K)] 2063041K(2063104K), 0.0024900 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
2016-04-14T20:34:31.751-0800: 42.564: [CMS-concurrent-sweep-start]
2016-04-14T20:34:31.760-0800: 42.573: [CMS-concurrent-sweep: 0.008/0.008 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
2016-04-14T20:34:31.760-0800: 42.573: [CMS-concurrent-reset-start]
2016-04-14T20:34:31.761-0800: 42.575: [CMS-concurrent-reset: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
在JVM各类GC日志剖析一文中可知,在使用CMS垃圾收集器时,Young GC阶段和Old GC的CMS-initial-mark,CMS-initial-mark,Rescan,Remark阶段是以Stop-The-World的形式执行,这样的确降低不少GC的暂停时间,但由于使用CMS后,可能导致GC次数上升,单位时间内,GC的总时间或许会占用更多,因此延迟时间(Latency)和吞吐量这两个维度的性能指标本身就是相生相克,但对于面向用户的应用,通常更注重延迟时间的性能指标。
如上面所述,当使用并行垃圾收集器(-XX:+UseParallelGC)时,虽然每次GC造成的应用暂停时间增加,但单位时间内,GC次数减少,GC的总时间或许会占用更少,因此保证了更多的CPU时间在执行应用程序,这种场景则比较适合非面向用户的应用,如一些后台计算任务,离线分析应用等。
容量作为应用的一些硬性限制,如内存,CPU等。针对容量调优,作得较多可能就是调整JVM堆大小,JVM堆分布等,如当需要适当减少比较耗时的Full GC次数,可以适当增大老年代,又或者适当增加对象晋升年龄(-XX:MaxTenuringThreshold=n)等。
在进行GC性能优化之前,通常需要借助一些工具来查看GC活动信息(如当前内存占用情况,内存容量,单个GC持续时间,GC不同阶段的持续时间等),从而诊断GC如何影响应用程序的性能,下面将介绍一些常用的工具。
JMX作为最基本的获取GC信息的方式,其也是JVM暴露内部运行时状态的标准方式,开发人员可以在应用程序内部使用JMX API,或者通过JMX Client进行远程访问,比较熟悉的JMX Client则是JConsole和JVisualVM(两者均通过安装对应的插件),jdk7u40之后有了另一个第三方工具Java Mission Control(可通过jmc命令运行)。为了通过JMX Client远程连接到目标JVM进程,需要在启动目标JVM进程时,开启jmx远程端口:
java -Dcom.sun.management.jmxremote.port=5432 -Dcom.sun.management.jmxremote.authenticate=false mainClass
初次运行jvisualvm,需要安装MBean插件VisualVM-MBeans,Mission Control已经自带MBean插件:
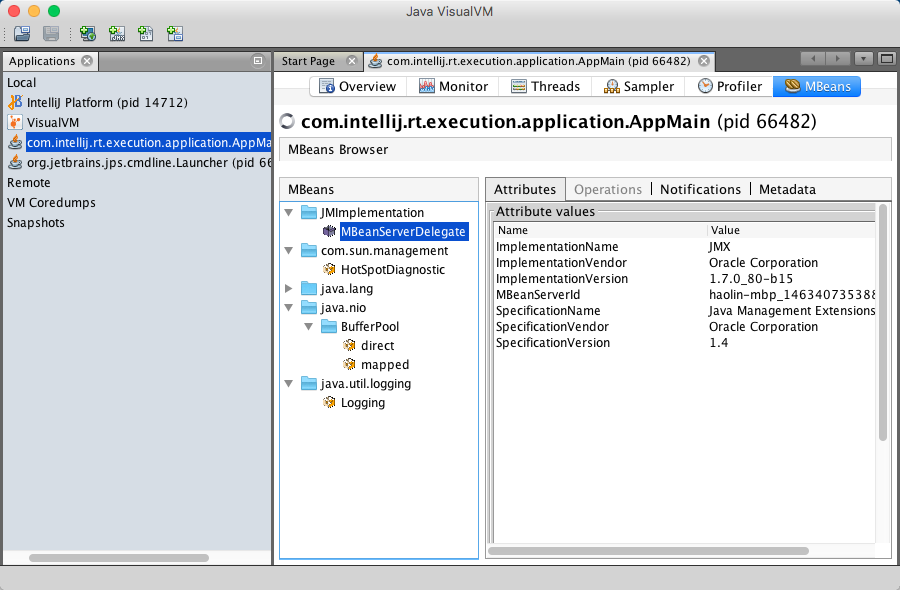
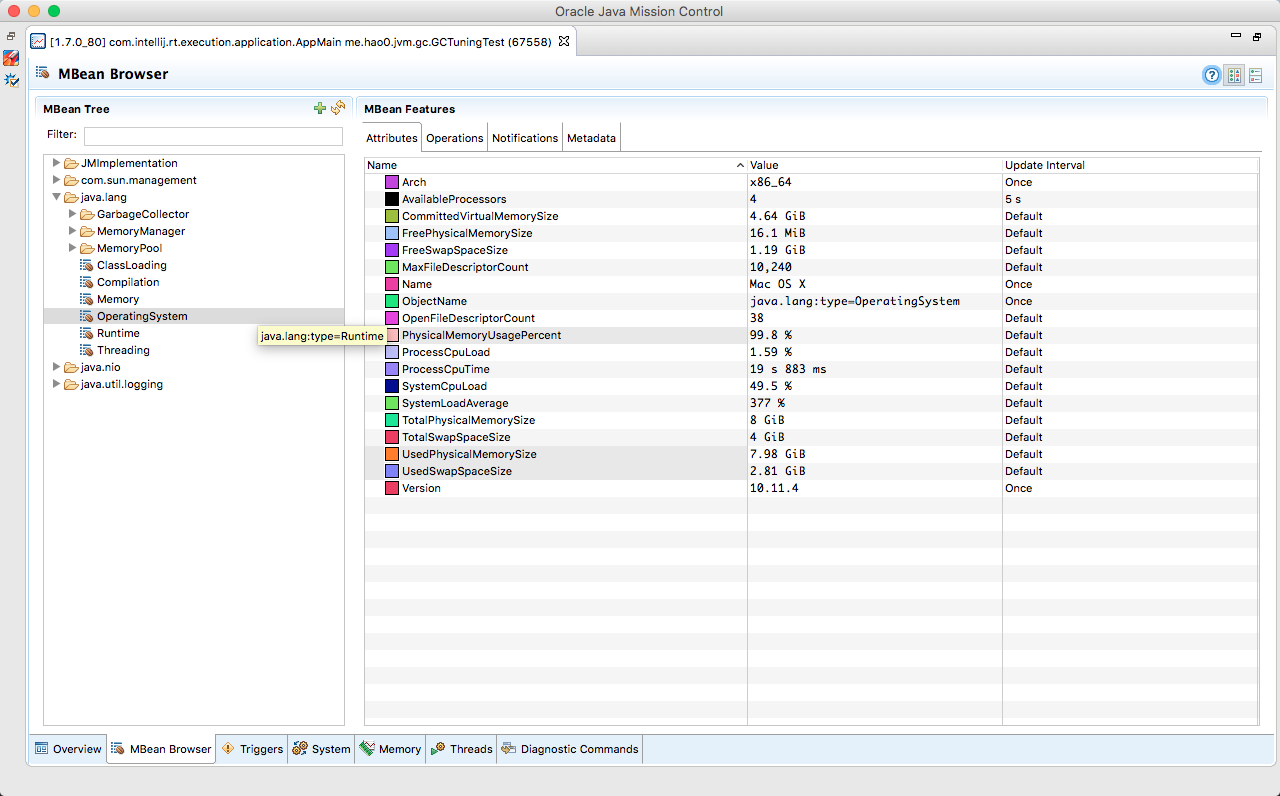
在java.lang.GarbageCollector目录下,能看到当前JVM正在使用的垃圾收集器,并且还暴露了一些其他信息:
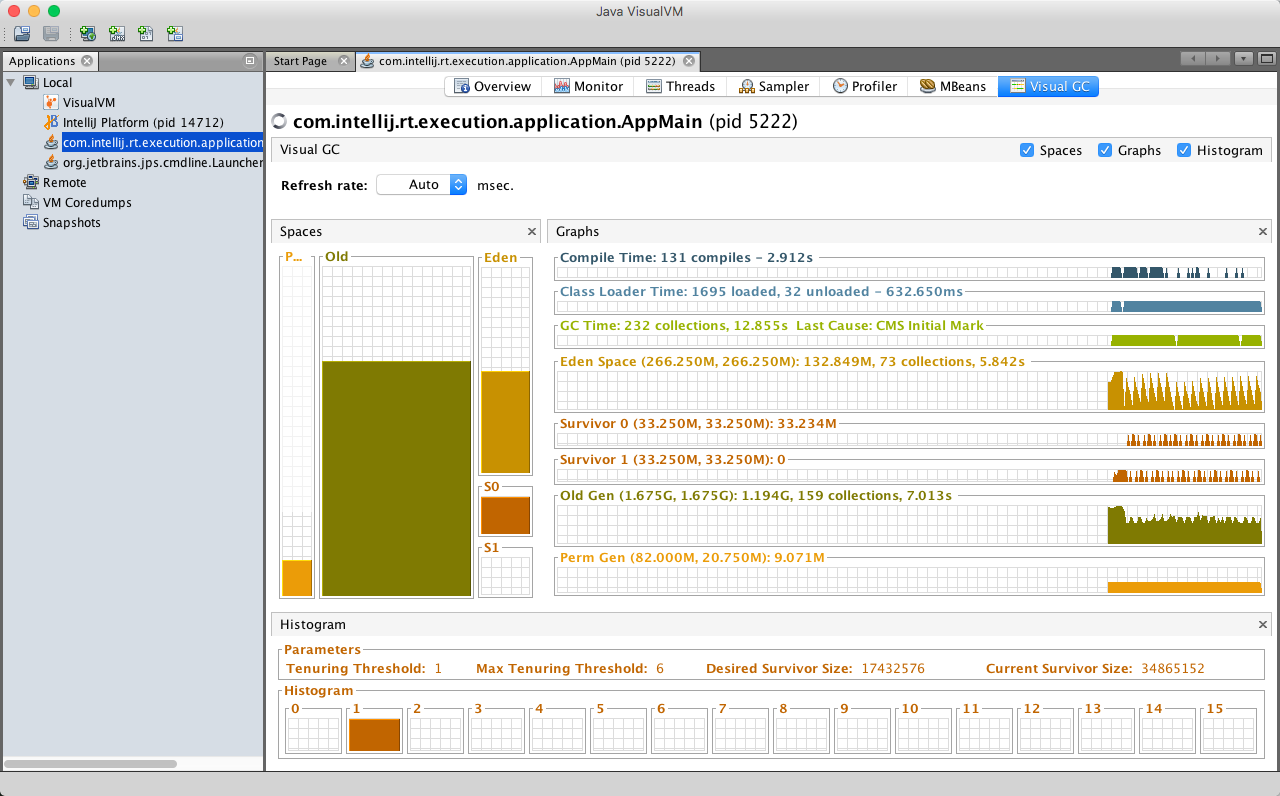
相比标准JMX Client提供的JVM基本信息,JVisualVM通过VisualGC插件,能够实时获取不同区GC的详细信息,如:
有些时候可能不能直接使用JConsole,JVisualVM等界面工具分析Java应用,这个时候jstat则可以发挥作用,其可以在命令直接监控JVM目标进程,并且提供较多可选项,如
| 可选项 | 样例 | 描述 |
|---|---|---|
| class |
|
类加载器相关的信息:
Loaded:加载的类的数量;
Bytes:加载的字节数;
Unloaded:卸载的类的数量;
Bytes:卸载的字节数;
Time:执行类加载和卸载的耗费时间。
|
| compiler |
|
JIT编译器相关的信息:
Compiled:完成编译的次数;
Failed:编译失败的次数;
Invalid:编译非法的次数;
Time:编译的时间;
FailedType:编译失败的类型;
FailedMethod:最近一次编译失败的类及其方法名。
|
| gc |
|
垃圾收集相关的信息:
S0C:Survivor 0区总内存;
S1C:Survivor 1区总内存;
S0U:Survivor 0区使用内存;
S1U:Survivor 1区使用内存;
EC:Eden区总内存;
EU:Eden区使用内存;
OC:Old区总内存;
OU:Old区使用内存;
PC:Perm区总内存;
PU:Perm区使用内存;
YGC:Young GC次数;
YGCT:Young GC总时间;
FGC:Full GC次数;
FGCT:Full GC总时间;
GCT:GC总时间。
|
| gccapacity |
|
分代容量及对应的区信息:
NGCMN:年轻代的最小内存;
NGCMX:年轻代的最大内存;
NGC:年轻代的当前内存;
S0C:Survivor 0区总内存;
S1C:Survivor 1区总内存;
EC:Eden区总内存;
OGCMN:老年代的最小内存;
OGCMX:老年代的最大内存;
OGC:老年代的当前内存;
OC:老年代的总内存;
PGCMN:永久代的最小内存;
PGCMX:永久代的最大内存;
PGC:永久代的当前内存;
PC:永久代的总内存;
YGC:Young GC次数;
FGC:Full GC次数。
|
| gccause |
|
垃圾收集统计信息(类似gcutil),及最近和当前的垃圾收集的触发事件信息:
S0:Survivor 0区的占用率;
S1:Survivor 1区的占用率;
E:Eden区的占用率;
O:Old区的占用率;
P:Perm区的占用率;
YGC:Young GC次数;
YGCT:Young GC总时间;
FGC:Full GC次数;
FGCT:Full GC总时间;
GCT:GC总时间;
LGCC:最近一次GC的原因;
GCC:当前GC的原因。
|
| gcnew |
|
年轻代相关的统计信息:
S0C:Survivor 0区总内存;
S1C:Survivor 1区总内存;
S0U:Survivor 0区使用内存;
S1U:Survivor 1区使用内存;
TT:对象晋升阈值;
MTT:对象最大晋升阈值;
DSS:期望的Survivor区内存大小;
EC:Eden区总内存;
EU:Eden区使用内存;
YGC:Young GC次数;
YGCT:Young GC总时间。
|
| gcnewcapacity |
|
年轻代大小及对应的空间信息:
NGCMN:年轻代的最小内存;
NGCMX:年轻代的最大内存;
NGC:年轻代的当前内存;
S0CMX:Survivor 0区最大内存;
S0C:Survivor 0区当前内存;
S1CMX:Survivor 1区最大内存;
S1C:Survivor 1区当前内存;
ECMX:Eden区总最大内存;
EC:Eden区当前内存;
YGC:Young GC次数;
FGC:Full GC次数。
|
| gcold |
|
老年代及永久代相关的统计信息:
PC:永久代总内存;
PU:永久代使用内存;
OC:老年代总内存;
OU:老年代使用内存;
YGC:Young GC次数;
FGC:Full GC次数;
FGCT:Full GC总时间;
GCT:GC总时间。
|
| gcoldcapacity |
|
老年代大小相关的信息:
OGCMN:老年代的最小内存;
OGCMX:老年代的最大内存;
OGC:老年代的当前内存;
OC:老年代的总内存;
YGC:Young GC次数;
FGC:Full GC次数;
FGCT:Full GC总时间;
GCT:GC总时间。
|
| gcpermcapacity |
|
永久代大小相关的信息:
PGCMN:永久代的最小内存;
PGCMX:永久代的最大内存;
PGC:永久代的当前内存;
PC:永久代的总内存;
YGC:Young GC次数;
FGC:Full GC次数;
FGCT:Full GC总时间;
GCT:GC总时间。
|
| gcutil |
|
垃圾收集相关的总结信息:可参见gccause的描述。 |
| printcompilation |
|
编译方法相关的信息:
Compiled:完成的编译次数;
Size:方法的字节数;
Type:编译类型;
Method:编译的类及其方法名。
|
GC日志作为跟踪GC活动最常用的手段,开发人员可以在启动Java应用前,配置GC日志文件,在JVM各类GC日志剖析一文中已分析了各类GC日志,可供参考:
-XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCDetails -Xloggc:<filename>
hprof作为JDK自带的工具,可以用于收集CPU使用和堆使用信息,如:
java -agentlib:hprof=heap=sites mainClass
默认会在Java应用当前工作目录生成java.hprof.txt文件:
SITES BEGIN (ordered by live bytes) Thu May 19 21:11:59 2016
percent live alloc'ed stack class
rank self accum bytes objs bytes objs trace name
1 99.21% 99.21% 314006176 5987 1963803672 60017 307974 byte[]
2 0.03% 99.25% 98080 94 98080 94 302675 byte[]
3 0.02% 99.27% 70936 94 70936 94 302696 byte[]
4 0.01% 99.28% 39600 807 40112 819 302815 byte[]
5 0.01% 99.29% 37160 929 41800 1045 300316 java.util.LinkedHashMap$Entry
6 0.01% 99.30% 32736 1023 76288 2384 300070 java.util.HashMap$Entry
SITES END
可见,99.21%的对象类型为byte[],可跟踪到TRACE 307974:
TRACE 307974:
me.hao0.jvm.gc.GCTuningTest.run(GCTuningTest.java:33)
java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:471)
java.util.concurrent.FutureTask.runAndReset(FutureTask.java:304)
java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:178)
可以看到byte[]在GCTuningTest的33行被创建:
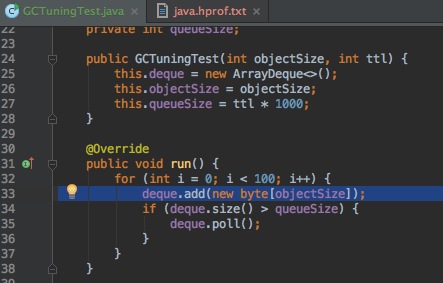
分配率指的是单位时间内,执行内存分配的次数,比如MB/sec。
0.291: [GC (Allocation Failure) [PSYoungGen: 33280K->5088K(38400K)] 33280K- >24360K(125952K), 0.0365286 secs] [Times: user=0.11 sys=0.02, real=0.04 secs]
0.446: [GC (Allocation Failure) [PSYoungGen: 38368K->5120K(71680K)] 57640K- >46240K(159232K), 0.0456796 secs] [Times: user=0.15 sys=0.02, real=0.04 secs]
0.829: [GC (Allocation Failure) [PSYoungGen: 71680K->5120K(71680K)] 112800K- >81912K(159232K), 0.0861795 secs] [Times: user=0.23 sys=0.03, real=0.09 secs]
从上面的GC日志可以计算出对象分配率:
| GC事件 | 发生时刻 | Young GC前 | Young GC后 | 分配的内存大小 | 分配率 |
|---|---|---|---|---|---|
| 1st GC | 291ms | 33280KB | 5088KB | 33280KB | 114MB/sec:[33280KB / 291ms] |
| 2nd GC | 446ms | 38368KB | 5120KB | 33280KB | 215MB/sec:[33280KB / (446ms - 291ms)] |
| 3rd GC | 829ms | 71680KB | 5120KB | 66560KB | 174MB/sec:[66560KB / (829ms - 446ms)] |
| Total | 829ms | N/A | N/A | 133120KB | 161MB/sec:[133120KB / 829ms] |
从上面的数据,可以看出内存分配率大概为161M/sec。那么内存分配率与哪些因素相关呢?由于新对象都在年轻代的Eden分配,因此可以判定内存分配率会与Eden大小有关,只要减少Minor GC次数,应用线程有更多的时间的分配对象,因此适当增加Eden大小(通过-XX:NewSize -XX:MaxNewSize & -XX:SurvivorRatio等参数)是可以提升内存分配率的。如下面的代码片段,当设置增加-XX:NewSize时,内存分配率也得到提升:
import java.util.concurrent.locks.LockSupport;
public class Boxing {
private static volatile Double sensorValue;
private static void readSensor() {
while(true) {
sensorValue = Math.random();
}
}
private static void processSensorValue(Double value) {
if(value != null) {
// Be warned: may take more than one usec on some machines, especially Windows
LockSupport.parkNanos(1000);
}
}
private static void initSensor() {
Thread sensorReader = new Thread(new Runnable() {
@Override
public void run() {
Boxing.readSensor();
}
});
sensorReader.setDaemon(true);
sensorReader.start();
}
public static void main(String[] args) {
int iterations = args.length > 0 ? Integer.parseInt(args[0]) : 1_000_000;
initSensor();
for(int i = 0; i < iterations; i ++) {
processSensorValue(sensorValue);
}
}
}
0.262: [GC [PSYoungGen: 9216K->416K(10240K)] 9216K->416K(31744K), 0.0016750 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.278: [GC [PSYoungGen: 9632K->432K(10240K)] 9632K->432K(31744K), 0.0010580 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.293: [GC [PSYoungGen: 9648K->400K(10240K)] 9648K->400K(31744K), 0.0009980 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.309: [GC [PSYoungGen: 9616K->384K(10240K)] 9616K->384K(31744K), 0.0010410 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
0.324: [GC [PSYoungGen: 9600K->384K(10240K)] 9600K->384K(31744K), 0.0010620 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.340: [GC [PSYoungGen: 9600K->368K(10240K)] 9600K->368K(31744K), 0.0011530 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
0.356: [GC [PSYoungGen: 10096K->32K(10240K)] 10096K->372K(31744K), 0.0012630 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.373: [GC [PSYoungGen: 9760K->32K(10240K)] 10100K->372K(31744K), 0.0004440 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
0.387: [GC [PSYoungGen: 9248K->32K(10240K)] 9588K->372K(31744K), 0.0003680 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.402: [GC [PSYoungGen: 9248K->32K(10240K)] 9588K->372K(31744K), 0.0004320 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
0.416: [GC [PSYoungGen: 9248K->32K(10240K)] 9588K->372K(31744K), 0.0005660 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.431: [GC [PSYoungGen: 9248K->32K(10240K)] 9588K->372K(31744K), 0.0003950 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
...
可以看出Young GC发生得十分频繁,每秒发生近70次,并且每次Young GC后内存占用都很少,并为引起Full GC,这导致GC时间增多,从而应用吞吐量下降,需要降低GC次数,此时可以尝试增加堆大小,如-Xmx128m:
0.196: [GC [PSYoungGen: 33792K->416K(38912K)] 33792K->416K(125952K), 0.0017080 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
0.250: [GC [PSYoungGen: 34208K->448K(38912K)] 34208K->448K(125952K), 0.0010780 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.309: [GC [PSYoungGen: 34240K->384K(38912K)] 34240K->384K(125952K), 0.0033450 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.367: [GC [PSYoungGen: 34176K->400K(38912K)] 34176K->400K(125952K), 0.0011970 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
0.419: [GC [PSYoungGen: 34192K->384K(38912K)] 34192K->384K(125952K), 0.0013190 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.471: [GC [PSYoungGen: 34176K->384K(38912K)] 34176K->384K(125952K), 0.0010080 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.530: [GC [PSYoungGen: 38784K->64K(38912K)] 38784K->408K(125952K), 0.0011870 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.590: [GC [PSYoungGen: 38464K->64K(43008K)] 38808K->408K(130048K), 0.0005810 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.659: [GC [PSYoungGen: 42048K->64K(43008K)] 42392K->408K(130048K), 0.0005950 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.733: [GC [PSYoungGen: 42048K->32K(43008K)] 42392K->376K(130048K), 0.0003790 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.796: [GC [PSYoungGen: 42016K->64K(43008K)] 42360K->408K(130048K), 0.0004490 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.862: [GC [PSYoungGen: 42048K->32K(43008K)] 42392K->376K(130048K), 0.0004920 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
可见,适当增加堆大小可以降低GC频率,从而也会提高应用吞吐量,但这可能并不会降低内存分配率,应当使用之前的工具,如hprof,分析具体的对象实例,从程序级别减少对象分配。如上面的代码,之所以发生频繁GC,主要是sensorValue = Math.random()不断地产生随机数,并装箱为Double类型,若将sensorValue声明为double基本类型,将不会产生新对象,仅仅是重写sensorValue的内存值,因此不会触发GC,当然对于这类情况,JIT会通过逃逸分析技术有可能做一些内部优化。
对于对象晋升,需要建立在晋升率之上,即单位时间内从年轻代晋升到老年代的数据量,通常也是MB/sec。对于存活时间长的对象,从年轻代晋升到老年代,这是正常的,但对于那些存活时间并不长的对象被提早晋升到老年代时就需要注意了,这会导致老年代内存占用增加过快,触发更多的Full GC,影响应用吞吐量,这就是对象过早晋升。
0.291: [GC (Allocation Failure) [PSYoungGen: 33280K->5088K(38400K)] 33280K- >24360K(125952K), 0.0365286 secs] [Times: user=0.11 sys=0.02, real=0.04 secs]
0.446: [GC (Allocation Failure) [PSYoungGen: 38368K->5120K(71680K)] 57640K- >46240K(159232K), 0.0456796 secs] [Times: user=0.15 sys=0.02, real=0.04 secs]
0.829: [GC (Allocation Failure) [PSYoungGen: 71680K->5120K(71680K)] 112800K- >81912K(159232K), 0.0861795 secs] [Times: user=0.23 sys=0.03, real=0.09 secs]
如上面的GC日志,可以计算出对象晋升率:
| GC事件 | 发生时刻 | 年轻代占用减少 | 整个堆占用减少 | 对象晋升大小 | 对象晋升率 |
|---|---|---|---|---|---|
| 1st GC | 291ms | 28192K | 8920K | 19272K | 约66.2MB/sec:[19272K / 291ms] |
| 2nd GC | 446ms | 33248K | 11400K | 21848K | 约140.95MB/sec:[21848K / (446ms - 291ms)] |
| 3rd GC | 829ms | 66560K | 30888K | 35672KB | 约93.14MB/sec:[35672KB / (829ms - 446ms)] |
| Total | 829ms | N/A | N/A | 76792K | 92.63MB/sec:[76792K / 829ms] |
如通过下面的代码片段:
public class PrematurePromotion {
private static final int MAX_CHUNKS = Integer.getInteger("max.chunks", 10_000);
private static final Collection<byte[]> accumulatedChunks = new ArrayList<>();
private static void onNewChunk(byte[] bytes) {
accumulatedChunks.add(bytes);
if (accumulatedChunks.size() > MAX_CHUNKS) {
processBatch(accumulatedChunks);
accumulatedChunks.clear();
}
}
public static void main(String[] args) {
while (true) {
onNewChunk(produceChunk());
}
}
private static byte[] produceChunk() {
byte[] bytes = new byte[1024];
for (int i = 0; i < bytes.length; i++) {
bytes[i] = (byte) (Math.random() * Byte.MAX_VALUE);
}
return bytes;
}
public static volatile byte sink;
public static void processBatch(Collection<byte[]> bytes) {
byte result = 0;
for (byte[] chunk : bytes) {
for (byte b : chunk) {
result ^= b;
}
}
sink = result;
}
}
设置JVM运行参数-Xmx24m -XX:NewSize=16m -XX:MaxTenuringThreshold=1 -XX:-UseAdaptiveSizePolicy -XX:+PrintGCDetails -XX:+PrintGCTimeStamps:
1.303: [Full GC [PSYoungGen: 2048K->0K(14336K)] [ParOldGen: 4702K->5347K(8192K)] 6750K->5347K(22528K) [PSPermGen: 3017K->3016K(21504K)], 0.0243080 secs] [Times: user=0.02 sys=0.00, real=0.03 secs]
1.771: [Full GC [PSYoungGen: 12288K->0K(14336K)] [ParOldGen: 5347K->7340K(8192K)] 17635K->7340K(22528K) [PSPermGen: 3016K->3016K(21504K)], 0.0144450 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
2.177: [Full GC [PSYoungGen: 12288K->1533K(14336K)] [ParOldGen: 7340K->7925K(8192K)] 19628K->9459K(22528K) [PSPermGen: 3016K->3016K(21504K)], 0.0097750 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
2.502: [Full GC [PSYoungGen: 12288K->2045K(14336K)] [ParOldGen: 7925K->8000K(8192K)] 20213K->10046K(22528K) [PSPermGen: 3016K->3016K(21504K)], 0.0104870 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
2.800: [Full GC [PSYoungGen: 12288K->2045K(14336K)] [ParOldGen: 8000K->8081K(8192K)] 20288K->10126K(22528K) [PSPermGen: 3016K->3016K(21504K)], 0.0100370 secs] [Times: user=0.03 sys=0.00, real=0.01 secs]
可以看到老年代内存一直居高不下,导致Full GC频率过高,因为不断有年轻代对象晋升到了老年代,这时需要适当增加年轻代大小试试:
-Xmx64m -XX:NewSize=32m -XX:MaxTenuringThreshold=1 -XX:-UseAdaptiveSizePolicy -XX:+PrintGCDetails -XX:+PrintGCTimeStamps
0.906: [GC [PSYoungGen: 24576K->2934K(28672K)] 24576K->2942K(61440K), 0.0025130 secs] [Times: user=0.01 sys=0.01, real=0.00 secs]
1.739: [GC [PSYoungGen: 27510K->4096K(28672K)] 27518K->7179K(61440K), 0.0045100 secs] [Times: user=0.01 sys=0.01, real=0.00 secs]
2.491: [GC [PSYoungGen: 28672K->544K(28672K)] 31755K->3635K(61440K), 0.0004640 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
3.185: [GC [PSYoungGen: 25120K->4096K(28672K)] 28211K->7955K(61440K), 0.0016830 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
3.874: [GC [PSYoungGen: 28672K->4096K(28672K)] 32531K->13499K(61440K), 0.0043180 secs] [Times: user=0.01 sys=0.01, real=0.00 secs]
4.572: [GC [PSYoungGen: 28672K->3136K(28672K)] 38075K->12539K(61440K), 0.0010040 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
5.251: [GC [PSYoungGen: 27712K->4096K(28672K)] 37115K->17171K(61440K), 0.0030520 secs] [Times: user=0.00 sys=0.01, real=0.00 secs]
5.944: [GC [PSYoungGen: 28672K->1440K(28672K)] 41747K->14515K(61440K), 0.0006500 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
6.627: [GC [PSYoungGen: 26016K->4096K(28672K)] 39091K->18963K(61440K), 0.0023020 secs] [Times: user=0.01 sys=0.01, real=0.01 secs]
7.315: [GC [PSYoungGen: 28672K->4096K(28672K)] 43539K->25539K(61440K), 0.0044950 secs] [Times: user=0.01 sys=0.01, real=0.01 secs]
8.002: [GC [PSYoungGen: 28672K->4064K(28672K)] 50115K->25507K(61440K), 0.0013080 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
8.677: [GC [PSYoungGen: 28640K->4096K(28672K)] 50083K->30243K(61440K), 0.0035480 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
8.681: [Full GC [PSYoungGen: 4096K->0K(28672K)] [ParOldGen: 26147K->8701K(32768K)] 30243K->8701K(61440K) [PSPermGen: 3017K->3016K(21504K)], 0.0132600 secs] [Times: user=0.03 sys=0.01, real=0.01 secs]
这里,除了通过增加年轻代内存大小,来降低对象晋升频率,还可以将max.chunks减小也可以达到类似的目的,还有些情况可能需要,如年轻代内存有较大空闲,但仍有对象晋升到老年代,则有可能是对象太大或存活周期太大,可以关注下参数-XX:PetenureSizeThreshold和-XX:MaxTenuringThreshold。
还有一个会影响GC的因素则是程序中的非强引用,即软引用(Soft Ref),弱引用(Weak Ref)及影子引用(Phantom Ref),它们具有各自的内存特性:
运行下面的代码片段,看看WeakReference如何影响GC:
public class WeakReferences {
private static final int OBJECT_SIZE = Integer.getInteger("obj.size", 192);
private static final int BUFFER_SIZE = Integer.getInteger("buf.size", 64 * 1024);
private static final boolean WEAK_REFS_FOR_ALL = Boolean.getBoolean("weak.refs");
private static Object makeObject() {
return new byte[OBJECT_SIZE];
}
public static volatile Object sink;
public static void main(String[] args) throws InterruptedException {
System.out.printf("Buffer size: %d; Object size: %d; Weak refs for all: %s%n", BUFFER_SIZE, OBJECT_SIZE, WEAK_REFS_FOR_ALL);
final Object substitute = makeObject(); // We want to create it in both scenarios so the footprint matches
final Object[] refs = new Object[BUFFER_SIZE];
System.gc(); // Clean up young gen
for (int index = 0;;) {
Object object = makeObject();
sink = object; // Prevent Escape Analysis from optimizing the allocation away
if (!WEAK_REFS_FOR_ALL) {
// 保证此时只会有一个对象被WeakReference引用
object = substitute;
}
refs[index++] = new WeakReference<>(object);
if (index == BUFFER_SIZE) {
// 标志对象可以被回收
Arrays.fill(refs, null);
index = 0;
}
}
}
}
运行该程序-Xmx24m -XX:NewSize=16m -XX:MaxTenuringThreshold=1 -XX:-UseAdaptiveSizePolicy -XX:+PrintGCDetails -XX:+PrintGCTimeStamps:
0.146: [GC [PSYoungGen: 1731K->768K(14336K)] 1731K->768K(22528K), 0.0024160 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
0.148: [Full GC [PSYoungGen: 768K->0K(14336K)] [ParOldGen: 0K->703K(8192K)] 768K->703K(22528K) [PSPermGen: 3457K->3456K(21504K)], 0.0188450 secs] [Times: user=0.03 sys=0.00, real=0.02 secs]
0.194: [GC [PSYoungGen: 12288K->1632K(14336K)] 12991K->2335K(22528K), 0.0076960 secs] [Times: user=0.02 sys=0.00, real=0.01 secs]
0.211: [GC [PSYoungGen: 13920K->1216K(14336K)] 14623K->1927K(22528K), 0.0045920 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
0.221: [GC [PSYoungGen: 13504K->832K(14336K)] 14215K->1551K(22528K), 0.0041330 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
0.227: [GC [PSYoungGen: 13120K->384K(14336K)] 13839K->1103K(22528K), 0.0026100 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
0.232: [GC [PSYoungGen: 12672K->1696K(14336K)] 13391K->2799K(22528K), 0.0103530 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
0.246: [GC [PSYoungGen: 13984K->1664K(14336K)] 15087K->2767K(22528K), 0.0065740 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
0.257: [GC [PSYoungGen: 13952K->1216K(14336K)] 15055K->2319K(22528K), 0.0049490 secs] [Times: user=0.01 sys=0.00, real=0.01 secs]
0.264: [GC [PSYoungGen: 13504K->832K(14336K)] 14607K->1935K(22528K), 0.0031930 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
0.269: [GC [PSYoungGen: 13120K->416K(14336K)] 14223K->1519K(22528K), 0.0022340 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
0.274: [GC [PSYoungGen: 12704K->1696K(14336K)] 13807K->3183K(22528K), 0.0071170 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
由于WEAK_REFS_FOR_ALL=false,object始终将被赋值为substitute,即最终所有WeakReference都指向同一个对象,其他申请的对象均为普通对象,因此这些对象将在Young GC阶段被回收,这就造成了频繁的Young GC。尝试将WEAK_REFS_FOR_ALL打开,-Dweak.refs=true:
0.402: [GC [PSYoungGen: 13504K->832K(14336K)] 19780K->8236K(22528K), 0.0089790 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
0.411: [Full GC [PSYoungGen: 832K->0K(14336K)] [ParOldGen: 7404K->8100K(8192K)] 8236K->8100K(22528K) [PSPermGen: 3459K->3459K(21504K)], 0.1004270 secs] [Times: user=0.17 sys=0.00, real=0.10 secs]
0.515: [Full GC [PSYoungGen: 12288K->204K(14336K)] [ParOldGen: 8100K->8175K(8192K)] 20388K->8380K(22528K) [PSPermGen: 3459K->3459K(21504K)], 0.0407580 secs] [Times: user=0.10 sys=0.01, real=0.04 secs]
0.559: [Full GC [PSYoungGen: 12288K->0K(14336K)] [ParOldGen: 8175K->7875K(8192K)] 20463K->7875K(22528K) [PSPermGen: 3459K->3459K(21504K)], 0.0506110 secs] [Times: user=0.11 sys=0.00, real=0.05 secs]
0.613: [Full GC [PSYoungGen: 12288K->0K(14336K)] [ParOldGen: 7875K->5160K(8192K)] 20163K->5160K(22528K) [PSPermGen: 3459K->3459K(21504K)], 0.0465770 secs] [Times: user=0.08 sys=0.00, real=0.04 secs]
0.663: [GC [PSYoungGen: 12288K->1216K(14336K)] 17448K->6376K(22528K), 0.0084050 secs] [Times: user=0.02 sys=0.00, real=0.00 secs]
这时,由于产生了很多WeakReference引用的对象,导致了偶尔频繁的Full GC,日常开发这样使用WeakReference是很常见的,比如用其作为Map中的Key等,所以还得尝试增加堆大小,-Xmx64m -XX:NewSize=32m,这将使得对象在Young GC就被回收。若将上面的WeakReference换为SoftReference,理论上将导致更频繁的Full GC,因为仅被SoftReference所引用的对象,只会在OutOfMemoryError之前被回收,可以通过-XX:+PrintReferenceGC查看引用对象的收集情况。
以上,则是有关JVM垃圾收集调优的基础,在调优之前,应事先明确应用性能是否由JVM GC引起,确定后在通过相关工具,定位具体的GC问题所在,再作参数调整和性能对比。以下是使用CMS时的VM配置Demo,必要是使用G1是不错的选择:
-server -Xms4096m -Xmx4096m -XX:MaxPermSize=512m -XX:+UseConcMarkSweepGC
-XX:CMSFullGCsBeforeCompaction=5 # 运行5次Full GC,进行一次内存压缩
-XX:+UseCMSCompactAtFullCollection # 打开对年老代的内存压缩
-XX:CMSInitiatingOccupancyFraction=80 # 老年代占用80%后,启动GC
Java GC指南
Java垃圾收集
JVM GC调优
JMX
JConsole使用
JVisualvm使用
JVM配置选项

