
-
什么是分布式系统调用跟踪
-
为什么需要跟踪分布式系统调用
-
分布式系统调用跟踪需要作些什么
-
分布式系统调用跟踪的基本模型
-
分布式系统调用跟踪的基本架构
-
低侵入性
-
高可用容错
-
高性能 & 低丢失率
-
分布式系统调用跟踪系统的架构设计
-
基于Dubbo的分布式系统调用跟踪实践
-
一个简单的Demo
-
其他问题
-
总结
-
参考文献
对于业务发展前期,可能我们会比较关注单个请求的耗时,频次等基本指标,以针对作出相应调整或优化。但随着系统业务发展,整个系统的调用链将变得愈发复杂,一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位服务故障点,以对症下药。于是就有了分布式系统调用跟踪的诞生。本文将阐述与分布式系统调用跟踪相关的一些实践经验。
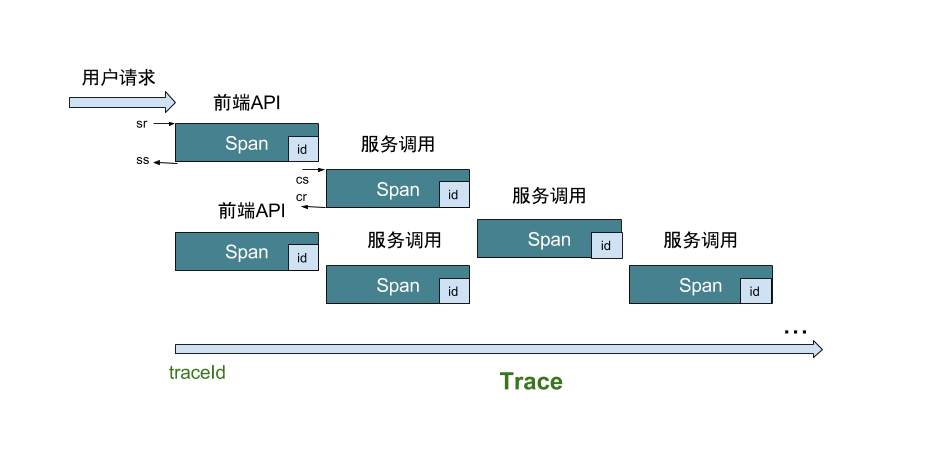
如图,在跟踪链中有以下几个比较重要的数据结构和概念:
对于一个基本的分布式系统调用跟踪系统,大致需要满足基本的特性:低侵入性,高性能,高可用容错,低丢失率等,下文绍这几个特性的简单实现。
对于业务系统而言,低侵入性是一个比较基础的特性,保证对业务开放人员的透明性,尽量减少代码级的侵入。对于分布式调用跟踪,跟踪事件发生在调用前后,因此可借助类似拦截器,过滤器,AOP等机制,利用配置代替编码。
在跟踪分布式调用过程中,应当保证跟踪系统具有高可用容错,首先保证跟踪服务器具有集群特性,不能出现单点,即便跟踪服务器均不可用,也不应影响到业务系统的稳定性,保持自身的轻量性。建议以日志文件的方式记录跟踪行为,再通过Collector来收集这些记录,输出到跟踪服务器。这样即便跟踪服务器不可用时,也不会影响到业务系统的运行。同时,使用了记录文件后,有便于以后针对高流量时,可适当做一些缓冲或流控方面的优化。
对于分布式调用跟踪,应该保证良好的性能,如上文所述,采用文件记录的方式肯定比直接通过网络传输更高效,结合一些高效的I/O手段,如使用高效的队列库Disruptor,在结合Java自身的MappedByteBuffer和RandomAccessFile的顺序写,随机读的方式,将达到一个可观的性能。除此外,MappedByteBuffer也保证,在应用将跟踪记录写入到内存后,若此时应用意外崩溃,但跟踪记录并不会丢失,而是由操作系统完成从内存到文件的同步工作,这进一步降低了记录丢失的发生。
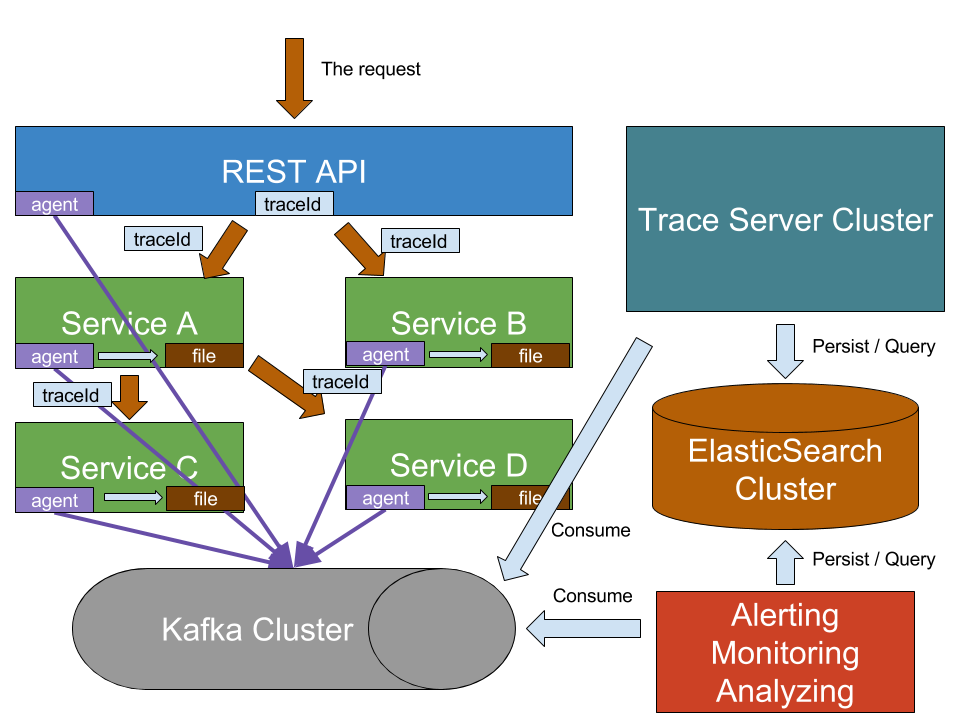
由于业务系统中,应用均以dubbo作为RPC框架,下面将以Zipkin作为跟踪服务器,做一些简单的实践。
假设现在前端有一个创建订单的请求,需要先调用到web应用的API,再分别调用订单服务和用户服务,订单服务还会间接调用用户服务,如下图所示:
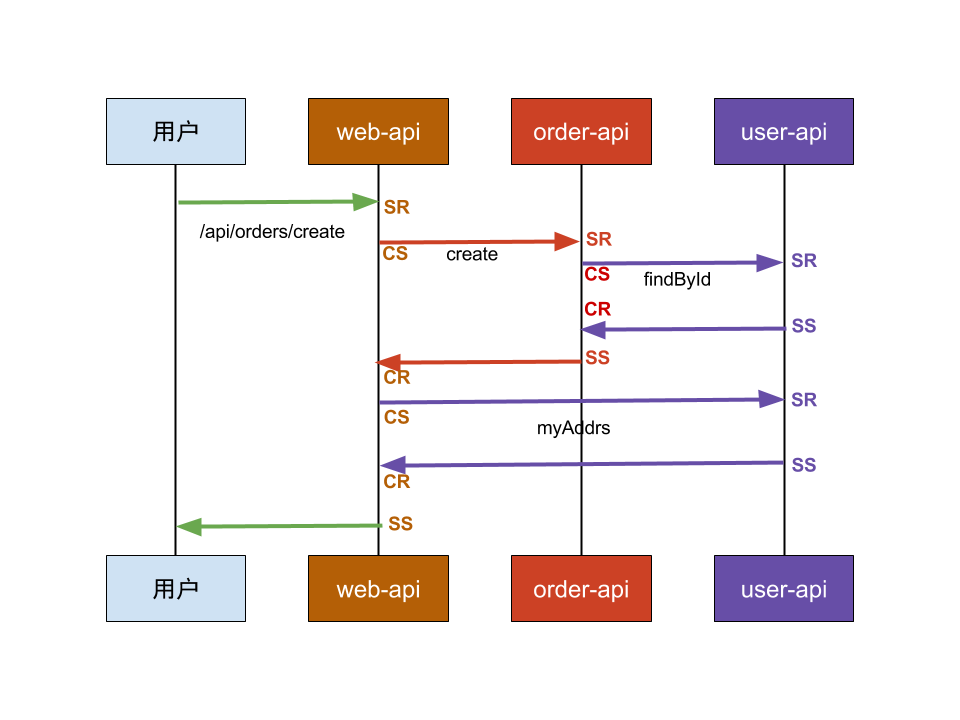
从图中可以看出,Web应用作为用户请求的第一层,因此,可以在Web应用层初始化整个调用链,包括traceId,rootSpanId等重要信息,对于ID生成,可以是UUID或64位整型,又或者根据自己的规则去生成。这个操作比较适合放在Filter中来作,但其实并不是每个请求都需要作跟踪,可以在配置文件中定义需要的跟踪的请求,如:
// TraceFilter
public void doFilter(ServletRequest request, ServletResponse response, FilterChain chain)
throws IOException, ServletException {
// 初始化根Span
Span rootSpan = startTrace(req);
// 将核心数据放入ThreadLocal
TraceContext.start();
TraceContext.setTraceId(rootSpan.getTrace_id());
TraceContext.setSpanId(rootSpan.getId());
TraceContext.addSpan(rootSpan);
// 执行其他filter及servlet
chain.doFilter(request, response);
// 结束跟踪,并收集Span信息
endTrace(req, rootSpan, watch);
}
private Span startTrace(HttpServletRequest req, TracePoint point) {
// ...
// 设置sr
apiSpan.addToAnnotations(
Annotation.create(timestamp, TraceConstants.ANNO_SR,
Endpoint.create(apiName, ServerInfo.IP4, req.getLocalPort())));
return apiSpan;
}
private void endTrace(HttpServletRequest req, Span span, Stopwatch watch) {
// 设置ss
span.addToAnnotations(
Annotation.create(Times.currentMicros(), TraceConstants.ANNO_SS,
Endpoint.create(span.getName(), ServerInfo.IP4, req.getLocalPort())));
// 计算耗时
span.setDuration(watch.stop().elapsed(TimeUnit.MICROSECONDS));
// 发送跟踪记录
agent.send(TraceContext.getSpans());
}
由于需要在整个请求链中共享traceId及父级spanId,因此将其放入ThreadLocal上下文。既然已经初始化了rootSpan,接下来我们还需要讲这里的traceId和spanId传递给后端的dubbo服务,这可以通过在dubbo提供的Filter中的attachment中设置,如:
// TraceConsumerFilter
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
// 消费者方开始跟踪服务调用,即cs
Span consumeSpan = startTrace(invoker, invocation);
// 发起远程调用
Result result = invoker.invoke(invocation);
// 远程调用结束,即cr
endTrace(invoker, result, consumeSpan, watch);
return result;
}
private Span startTrace(Invoker<?> invoker, Invocation invocation){
// ...
// 将traceId,spanId放入调用上下文
Map<String, String> attaches = invocation.getAttachments();
attaches.put(TraceConstants.TRACE_ID, String.valueOf(consumeSpan.getTrace_id()));
attaches.put(TraceConstants.SPAN_ID, String.valueOf(consumeSpan.getId()));
// ...
}
这样在provider端就能获取到当前traceId和spanId,由于在provider端仍然还有可能调用其他dubbo服务,因此provider端接收到consumer传递的traceId和spanId后,还需要将其设置在ThreadLocal中,以便后续的dubbo服务调用中也需要传递traceId和spanId,如:
// TraceProviderFilter
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
// ...
Map<String, String> attaches = invocation.getAttachments();
if (!attaches.containsKey(TraceConstants.TRACE_ID)){
// 没有必要跟踪该请求
return invoker.invoke(invocation);
}
// prepare trace context
startTrace(attaches);
Result result = invoker.invoke(invocation);
endTrace();
return rpcResult;
}
private void startTrace(Map<String, String> attaches) {
// 设置traceId和spanId到ThreadLocal
long traceId = Long.parseLong(attaches.get(TraceConstants.TRACE_ID));
long parentSpanId = Long.parseLong(attaches.get(TraceConstants.SPAN_ID));
TraceContext.start();
TraceContext.setTraceId(traceId);
TraceContext.setSpanId(parentSpanId);
}
private void endTrace() {
// 发送跟踪记录
agent.send(TraceContext.getSpans());
// 清空ThreadLocal
TraceContext.clear();
}
这样,当在前端发起请求后,则会在跟踪服务器生成对应的跟踪记录:

以上,则是有关分布式系统调用跟踪的实践,这对于发现应用瓶颈,排查问题及服务依赖优化都比较重要,希望对读者有所帮助。

