
-
日志平台构建背景
-
如何构建日志平台
-
日志平台实践
-
日志规范
-
Logstash
-
下载 & 安装
-
配置
-
比Logstash更好的选择
-
下载 & 安装
-
配置
-
ElasticSearch
-
日志Mapping
-
Kibana
-
下载 & 部署
-
配置
-
其他相关
-
基于日志的统计分析监控平台设计
-
基于本地日志文件
-
日志收集的高可用性
-
总结
随着业务不断扩大,系统产生的各种日志也已经趋于暴涨,要想从这些庞大的日志中检索出自己想要的信息,特别是一些错误信息,是至关重要的。对于一个比较成熟的日志平台,需要解决几个问题:如何规范日志,如何收集日志,如何传输日志,如何存储日志,如何分析展示日志等等,恰逢最近需要为业务团队提供日志服务,旨在能及时发现并解决线上出现的异常问题,主要是从ELK Stack出发进行日志平台构建,本文将阐述其中的一些细节和思路。
随着业务系统的不断增长,应用产生的日志会越来越庞大,则对这些日志进行收集,检索,分析,监控等操作,这些东西将成为开发人员分析和排查问题的利器。最近由于应用服务不断扩容,基本每个应用服务的实例会在10个以上,这对开发人员需要快速查看日志带来很大问题,所以需要将一些重要的日志信息(错误,警告等)收集起来,并作友好展示。
如何收集日志
收集日志,即将应用或系统产生的日志进行近实时收集,通常可以理解为Linux中的tail -f命令,比较流行的收集工具大概有Scribe,Flume,Logstash等。Scribe由Facebook基于Thrift协议开发,因此适用于任何语言;Flume托管于Apache,其主要目的是将日志数据输出到HDFS,但通过定制Sink组件,可以将日志输出到其他存储中;Logstash作为ElasticSearch社区的产物,通过一些简单的配置就能对日志进行收集(Input),过滤/格式化(Filter),输出(Output)等操作,并提供丰富的插件,基本需要的功能都能满足,最终也选定Logstash作为日志收集Agent。
如何传输日志
对于日志传输,通常可以由日志收集Agent,直接将日志传输到目标存储中,即:
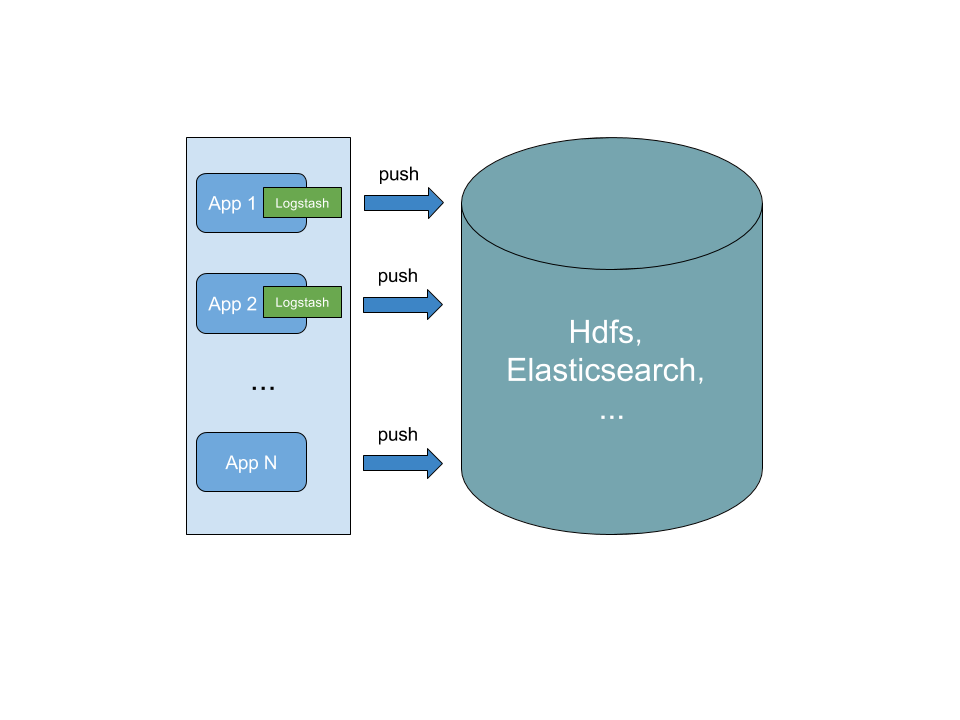
但随着业务日志膨胀,直接将日志输出的目标存储,有可能给存储系统带来比较大的压力,影响到日志Agent的输出性能,最终有可能造成日志积压,所以通常会在日志Agent和目标存储之间加上一层Buffer,来平衡之间的性能,通常比较常用的会有Redis,Kafka等,Kafka为日志而生,无疑是最佳之选,有了Kafka,不仅起到缓冲的作用,也便于当接入其他日志消费系统,能够直接通过消息订阅的方式,可以无缝接入:
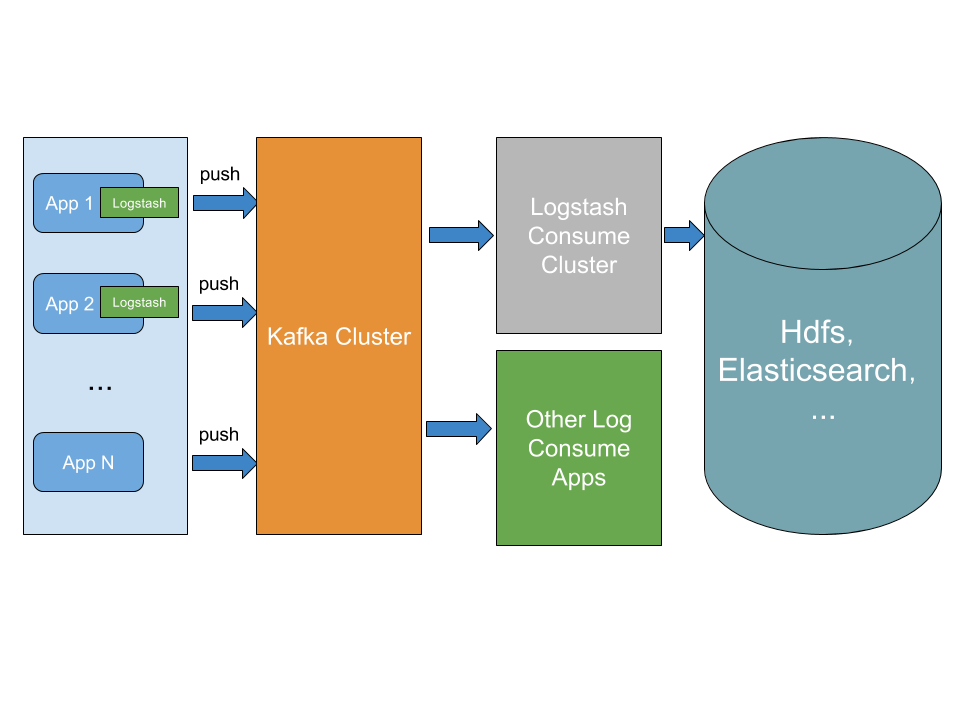
如何存储日志
对于日志存储,则就没有太统一的答案,这得看需要通过日志作什么,但通常都会涉及HDFS(便于后期作一些实时及离线分析),ElasticSearch(可以同Kinaba组合,做日志检索,报表统计等),当然还有可能会有自己定制的平台,需要保存日志到其他存储系统。
如何分析展示日志
对于日志分析展示,ElasticSearch社区也为我们提供了强大的工具Kibana,其提供了一些检索,报表统计等功能,但其用户权限等功能不是很完善,现实中,可能更希望作一些日志实时,离线分析,业务定制化的东西比较多,更合理的是通过一些专门的数据分析系统来作,如Spark,JStorm,Heron等。
在进行日志收集前,最好是做一些日志格式规范的工作,当前也可以不作,但格式化日志的操作无疑抛给了日志收集组件或日志分析组件,如类似下面的日志格式:
2016-06-06 18:06:52.478+0800 ERROR myapp2 lin 10.75.166.137 10236 [login] [haha, you are so cool]
Logstash作为日志收集Agent,需要安装在需要进行日志采集的应用服务器上,通常不同纬度的日志可以安装不同的Agent。
Logstash安装部署十分简单,即下即用:
wget https://download.elastic.co/logstash/logstash/logstash-2.3.4.tar.gz
tar zxf logstash-2.3.4.tar.gz
./logstash-2.3.4/bin/logstash -f /path/to/logstash.conf
Logstash配置也很简单,如:
# 日志输入配置
input {
# 输入插件配置
}
# 日志过滤配置(可选)
filter {
# 过滤插件配置
}
# 日志输出配置
output {
# 输出插件配置
}
Logstash配置也十分清晰,具体详细配置可参考这里。针对上面的日志格式,对应的配置大概如下:
input {
# file-input插件制定需要收集的日志文件
file {
path => "/path/to/xxx.log"
}
}
filter {
# grok-filter是最常见的过滤插件,用于将日志文本结构化
grok {
match => { "message" => "(?<log_time>[\s\S]*?) %{WORD:level} (?<app_name>[\s\S]*?[-][\s\S]*?) (?<app_owner>[\s\S,]*?) %{IP:app_ip} %{NUMBER:app_pid} _(?<tag>[\s\S]*?)_ _\[(?<detail>[\s\S\n]*?)\]_" }
}
}
output {
# elasticsearch-output插件,将filter后的内容输出到ElasticSearch
elasticsearch {
# elasticsearch hosts
hosts => ["10.112.88.105:9200"]
# index type
index => business_logs
# document type
document_type => business_log
}
}
其中,一个比较关键的是grok的match部分,这部分正则表达式应尽量简单,与日志规范密切配置,对于调试正则表达式匹配,建议先使用Grok Debugger工具测试好再部署,这样经过filter之后的日志内容将格式化为如下的json,再经过HTTP请求,发送至ElasticSearch:
{
"log_time": "",
"level": "",
"app_name": "",
"app_owner": "",
"app_ip": "",
"app_pid": "",
"tag": "",
"detail": ""
}
除了上面的字段,Logstash会加上一些自带的字段,只是我们不需要关心,或通过mutate-filter移除不需要的字段。
对于Logstash本身,也是会消耗系统资源(如内存,CPU等)的,特别当对日志进行过滤,格式化(如正则匹配操作等)时,是比较耗CPU的,所以有了下一代Logstash的诞生--Beat,若收集对象为文件,则可以使用Filebeat,其结构大致如下:
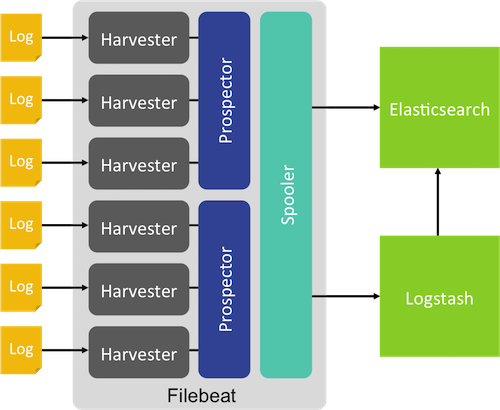
Filebeat安装部署同样十分简单,即下即用:
# redhat or centos
curl -L -O https://download.elastic.co/beats/filebeat/filebeat-1.2.3-x86_64.rpm
sudo rpm -vi filebeat-1.2.3-x86_64.rpm
filebeat -c /path/to/filebeat_config.yml -cpuprofile /path/to/cpu_prof -memprofile /path/to/mem_prof
Filebeat配置文件为YAML格式,一些基本配置如下,详细配置可见这里:
filebeat:
# prospector列表
prospectors:
-
paths: # 可配置多个日志路径
- "/path/to/*.log"
- "/path/to/*/*/*.log"
# 输出到ElasticSearch时,指定的document类型,默认为log
document_type: log
# 使用什么编码格式读取文件
encoding: utf-8
# 输入类型,
# log:从日志文件读取(默认)
# stdin: 从标准输入读取
input_type: log
# 仅保留匹配以下正则表达式的文本行,
include_lines: ["^ERR", "^WARN"]
# 当文本行匹配到其中的正则表达式时,则被丢弃;
# 对于支持multiline时,会先将multiline组合成一行,再进行匹配
# Filebeat会先匹配include_lines,再匹配exclude_lines
exclude_lines: ["^DBG", "^TEST"]
# 忽略某些文件
exclude_files: [".gz$"]
# prospector每隔多久检查一次是否有新文件
scan_frequency: 1s
# 每个harvester抓取文件时,使用的buffer大小(B)
harvester_buffer_size: 16384
# 单条日志消息的大小限制,超过改值的内容将被舍弃
max_bytes: 10485760
# 处理多行的消息,如Java中的异常堆栈消息,对应之上的
multiline:
# 以_[开头
start_pattern: _\[
# 以]_结尾
end_pattern: \]_
# 定义的pattern是否是否定的,即不匹配
negate: false
match: after
# 最多保留200行
max_lines: 200
# 超过了该时间,即使没有匹配完成,也会发送multiline event
timeout: 5s
# 从文件尾开始读
# 当设置为true时,有可能由于滚动产生的新文件日志太快,filebeat还未开始跟踪新文件,将会丢失filebeat跟踪该文件之前的日志
tail_files: false
# 每隔1s检查文件的更新
backoff: 1s
#
max_backoff: 10s
# backoff增加的乘法因子
backoff_factor: 2
# 当文件名更新时,是否强制关闭文件句柄
force_close_files: false
# 若Spooler中的事件数超过了该值,将强制进行网络flush
spool_size: 2048
# 设置为true时,publisher等待ACK的同时,会准备下次要发送的数据,这可以提升吞吐量,但却会消耗更多的内存
publish_async: false
#
idle_timeout: 5s
# 记录filebeat跟踪的文件信息
registry_file: /path/to/registry
# 输出配置
output:
# 输出到logstash
logstash:
# logstash hosts
hosts: ["10.112.88.153:5044","10.112.88.158:5044"]
# 输出到每个logstash host的worker数
worker: 1
# 压缩级别
compression_level: 3
# 开启负载均衡
loadbalance: true
# 日志配置
logging:
# 不输出到syslog
to_syslog: false
# 输出到文件
to_files: true
files:
# 文件目录
path: /path/to/log
# 文件名称
name: filebeat
# 每100M滚动文件
rotateeverybytes: 104857600 # = 100MB
# 保留7个文件
keepfiles: 7
# 日志级别
level: warning
若使用了Filebeat来收集日志,上面的Logstash的输入源将不再是文件,而是Filebeat:
input {
beats {
port => 5044
}
}
...
ElasticSearch作为存储,通常应该提供集群部署。但在进行搭建前,最好先确定好ElasticSearch的版本信息,ElasticSearch版本更新,对API的更新比较频繁,需要关注下所使用的插件是否支持对应的ElasticSearch版本,特别是有关中文分词的插件,相关的部署安装可以参考下这篇文章。
在日志收集前,需要提前在ElasticSearch集群中建立索引和映射,如针对上述的日志需要执行:
# 创建索引
curl -XPUT http://10.112.88.105:9200/business_logs?pretty
# 创建映射
curl -XPUT http://10.112.88.105:9200/business_logs/_mapping/business_log?pretty -d '
{
"business_log": {
"_all" : {
"enabled" : false
},
"properties": {
"log_time": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss.SSSZ"
},
"level": {
"type": "string",
"index" : "not_analyzed"
},
"app_name": {
"type": "string",
"index" : "not_analyzed"
},
"app_owner": {
"type": "string",
"index" : "not_analyzed"
},
"app_ip": {
"type": "string",
"index" : "not_analyzed"
},
"app_pid": {
"type": "integer",
"index" : "not_analyzed"
},
"tag": {
"type": "string",
"index_analyzer": "ik",
"search_analyzer": "ik"
},
"detail": {
"type": "string",
"index" : "not_analyzed"
}
}
}
}'
Kibana作为展示组件,也提供十分丰富的检索分析的功能,官方也提供一个比较靠谱的案例。
Kibana安装部署依然十分简单,即下即用:
wget https://download.elastic.co/kibana/kibana/kibana-x.x.x.tar.gz
tar zxf kibana-x.x.x-linux-x64.tar.gz
./${KIBANA_HOME}/bin/kibana
Kibana基本配置如下,详细配置可见这里:
# 绑定端口
port: 5601
# 绑定IP, 内网即可
host: "127.0.0.1"
# ElasticSearch地址
elasticsearch_url: "http://10.112.88.105:9200"
# preserve_elasticsearch_host true will send the hostname specified in `elasticsearch`. If you set it to false,
# then the host you use to connect to *this* Kibana instance will be sent.
elasticsearch_preserve_host: true
# 用于存储kibana数据信息的索引
kibana_index: ".kibana"
# 若ElasticSearch需要用户名/密码认证
# kibana_elasticsearch_username: user
# kibana_elasticsearch_password: pass
# 若ElasticSearch开启了客户端证书认证,则需要配置证书信息
# kibana_elasticsearch_client_crt: /path/to/your/client.crt
# kibana_elasticsearch_client_key: /path/to/your/client.key
# CA认证支持
# ca: /path/to/your/CA.pem
# 进入Kibana时,默认加载的应用
default_app_id: "discover"
# 等待ElasticSearch Ping响应的超时
# ping_timeout: 1500
# 请求ElasticSearch超时
request_timeout: 300000
# 启动Kibana时,等待ElasticSerach超时的时间
# startup_timeout: 5000
# 是否验证SSL
verify_ssl: true
# SSL验证需要的KEY
# ssl_key_file: /path/to/your/server.key
# ssl_cert_file: /path/to/your/server.crt
# pid文件
# pid_file: /var/run/kibana.pid
# 日志文件
# log_file: ./kibana.log
# A value to use as a XSRF token. This token is sent back to the server on each request
# and required if you want to execute requests from other clients (like curl).
# xsrf_token: ""
# 该kibana包中已经内置的插件,不需要在plugins/目录下配置了
bundled_plugin_ids:
- plugins/dashboard/index
- plugins/discover/index
- plugins/doc/index
- plugins/kibana/index
- plugins/markdown_vis/index
- plugins/metric_vis/index
- plugins/settings/index
- plugins/table_vis/index
- plugins/vis_types/index
- plugins/visualize/index
部署完毕后,就可以打开Kibana,添加对应需要分析的数据了:
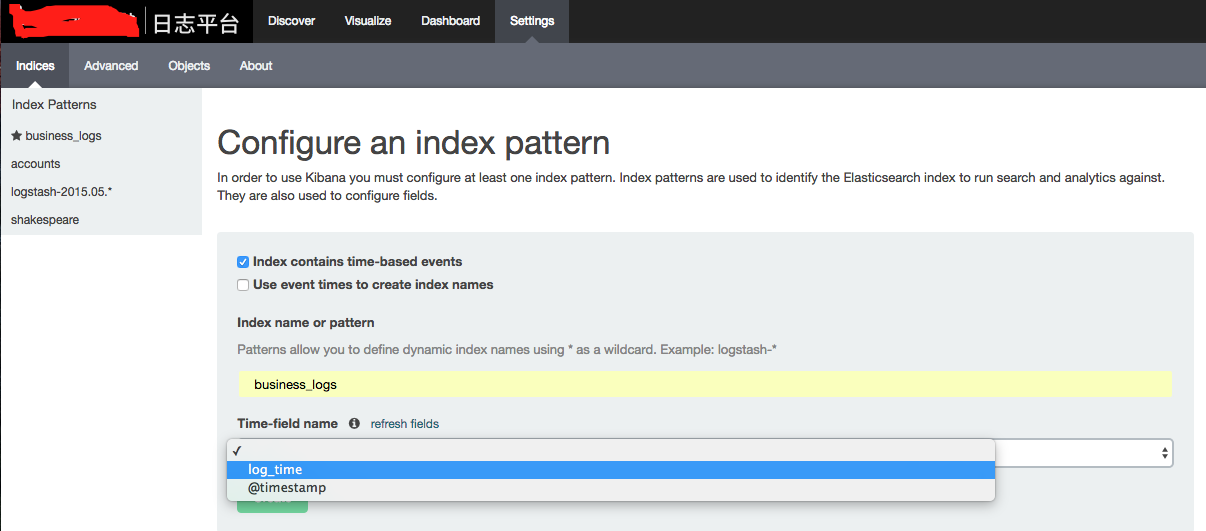
配置index_pattern时,需要指定时间字段,如log_time,这里需要注意,Kibana对时间字段,会作时区处理,因此日志信息中需要加入时区信息,即日志格式应保证有Z,如上述的yyyy-MM-dd HH:mm:ss.SSSZ,之后就能在Kibana的Discover中检索了:

这样一个日志平台的基础功能就实现了。
一个比较完善的日志统计分析监控平台,大致会如下:
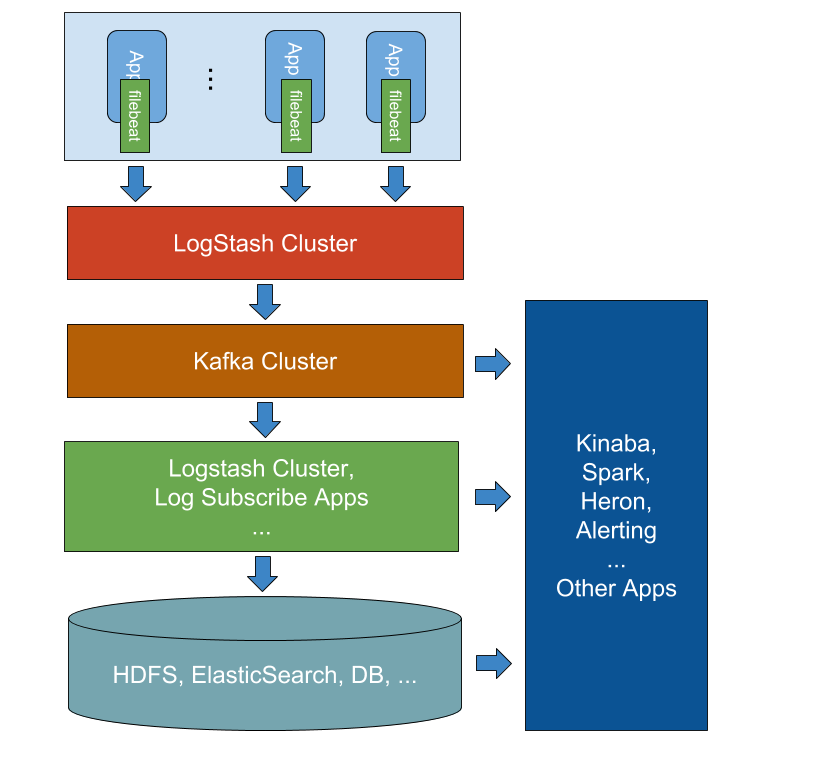
对于收集操作,通常都是通过Agent在应用实例所在服务器中,收集其本地日志,而不是直接通过应用直接输出到远端(比如,对于java应用,通过定制Logger对象),这其实不是很友好的,一旦远端日志系统不可用,既影响应用系统稳定,又会丢失消息,因此最好先写到磁盘,再收集日志,对应用端无感。
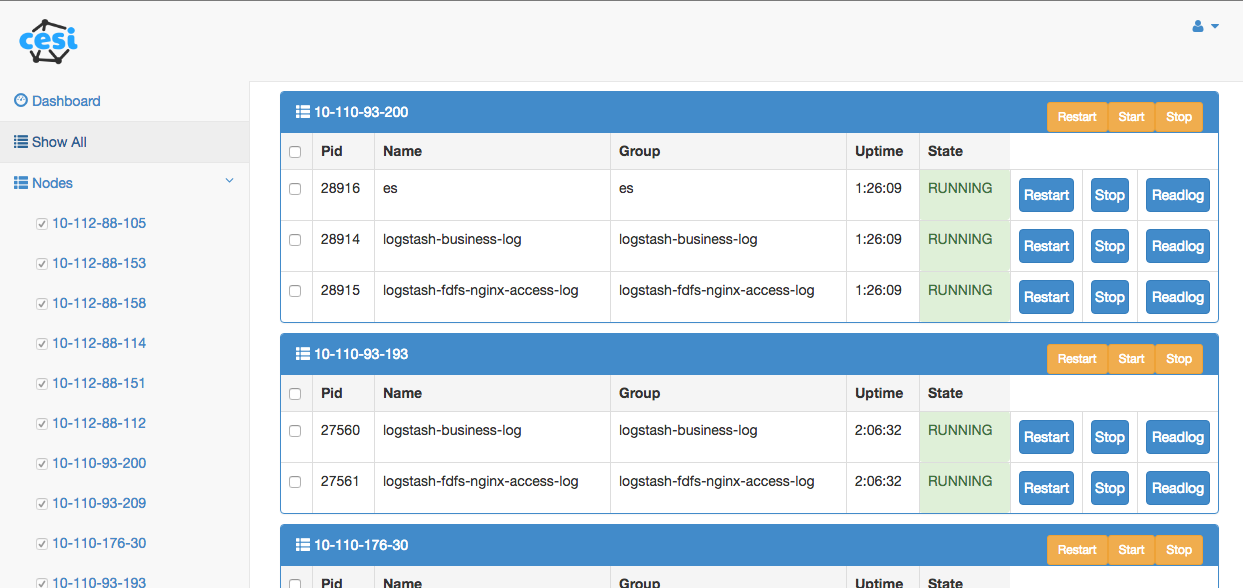
实际中,难免可能碰到日志Agent不可用,即日志不能被同步到日志平台,而日志收集这类组件本身并没有什么状态依赖,因此可以考虑使用进程管理工具Supervisor,对这些日志Agent统一管理,如自动重启等。而对于Supervisord进程本身,也是有崩溃几率的,不过可以通过系统级的进程监控,开机自启动等手段保证一定的高可用性。cesi通过Supervisord提供的XML-RPC,实现对Supervisord所管理的进程一些简单操作:
以上,则是基于ELK Stack的日志平台构建,当然不仅限于业务日志,在大数据统计分析中,依然可以通过日志来作,其他如监控,报警,性能分析,调用链分析,个人觉得都可以通过日志的方式来处理。

