
-
哈希(Hash)
-
一致性哈希(Consistent Hash)
-
利用哈希实现缓存
- 然而,对于上面的做法并没有不对,只是有一些不完善的地方:
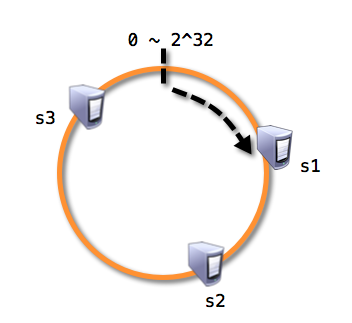
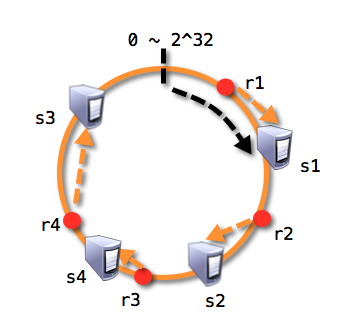
- 若使用一致性哈希将解决上面的问题, 一致性哈希首先会将缓存服务器节点分布在一个哈希值范围为0~2^32的圆环内:
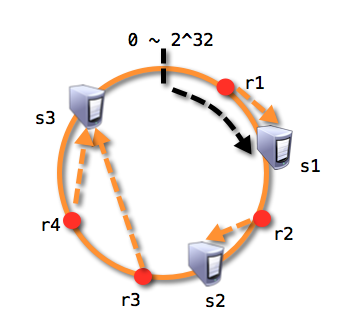
- 再通过同样的哈希算法将资源映射到环内, 这样r1将存放在s1服务器上,r2存放在s2服务器上,r3,r4存在在s3服务器上:
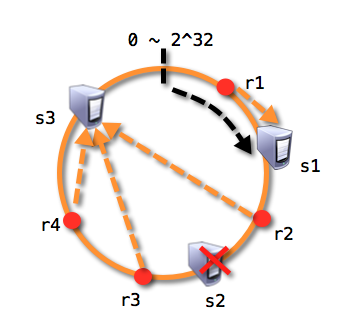
- 若此时s2服务器发生崩溃,受影响的仅是s1与s2之间的资源,将被映射到s3上:
- 又或者s2与s3之间增加了s4,此时受影响的仅是s4与s2之间的资源,将被映射到s4上:
- 那么可以看下如何将缓存服务器节点和资源哈希到环上:
- 当定位资源r时,也会通过同样的hash函数,以下为java实现:
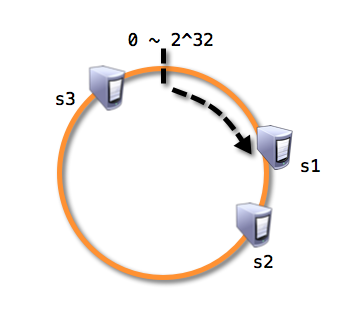
- 这样就能将资源映射到对应缓存服务器了,但当前的方案还是有一些问题,当缓存服务器节点比较少时, 会存在资源映射不均衡的情况,如:
- 显然,s3承担了比s1,s2都多的工作,这时,可以引入虚拟节点, 使得一个物理节点能够对应多个虚拟节点,从极限思维,达到节点分布均匀:
- 这样,一致性哈希就弥补了一般哈希的两点不足,完整代码摘自别人,作了些小调整。
-
实际问题
如今,哈希已经被广泛应用在各种系统及应用中, 而一致性哈希则是其中一种常用的服务均衡算法, 旨在P2P环境中,如何在动态的网络中分布和路由节点,
哈希,也即散列, 旨在通过关键字(Key)而直接访问在内存存储位置的数据结构(value=hash(key)), 它通过计算一个关于键值的函数(hash算法),将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数称做散列函数, 存放记录的数组称做散列表。
与一般哈希不同,一致性哈希是一种特殊的哈希算法,在使用一致性哈希算法后,哈希表槽位数(大小)的改变平均只需要对K/n个关键字重新映射,其中 K是关键字的数量,n是槽位数量。然而在传统的哈希中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
对于一般哈希而言,当对资源r进行存取时,通过哈希取模公式hash(r) mod n就能定位到资源所在的缓存服务器,如
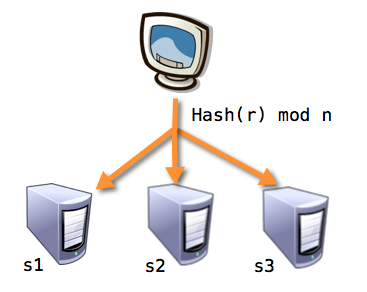
1. 该哈希算法不能保证负载均衡: 即多个缓存服务器所存放的资源会不够均衡,一些节点负载肯可能很高,一些则比较低;
2. 在缓存服务器节点数量发生变化时,哈希取模公式就得发生变化hash(r) mod n',这时,资源r与原有缓存服务器的映射关系将被打破,并且影响很大。
// node通常为Server主机地址
private void addNode(String node) {
// 通过md5出一个长度为16的字节数组
byte[] digest = md5(node.toString());
for (int h = 0; h < 4; h++) {
// 将hash值映射到Server节点
circle.put(hash(digest, h), node);
}
}
private byte[] md5(String text) {
md5Algorithm.update(text.getBytes());
return md5Algorithm.digest();
}
/**
* 产生一个32位数
*/
private long hash(byte[] digest, int h) {
return ((long) (digest[3 + h * 4] & 0xFF) << 24) |
((long) (digest[2 + h * 4] & 0xFF) << 16) |
((long) (digest[1 + h * 4] & 0xFF) << 8) |
(digest[h * 4] & 0xFF);
}
public T get(Object key) {
// 由同一hash函数计算出哈希值
long hash = hash(key.toString());
if (!circle.containsKey(hash)) {
// circle 为 TreeMap对象,tailMap将获取Key大于hash的map子集(即环上该hash顺时针后的所有子集)
SortedMap tailMap = circle.tailMap(hash);
// 若存在后续子集,取最近的hash,否则取环上第一个hash值,也就是第一个Server
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
// 获取hash值映射的Server节点
return circle.get(hash);
}
private void addNode(T node) {
// 添加物理节点时,则添加虚拟节点
for (int i = 0; i < virtual / 4; i++) {
byte[] digest = md5(node.toString() + i);
for (int h = 0; h < 4; h++) {
circle.put(hash(digest, h), node);
}
}
}
最近需要对推送服务支持多节点功能,即客户端注册时,会分配一个clientId,与此同时会返回,通过clientId进行 一致性哈希获取事先已经建立了哈希环的Server集群中的一个Server, 之后客户端就与该Server开始TCP通信, 通过一致性哈希也比较柔和地解决Server异常崩溃,或者动态增加Server的情况, 但还是会由于Server只有2个(服务器资源紧缺),在其中一个Server重启时, 导致该Server之前的Client会全部导向另一个Server,即便第一个Server启动完毕,之前的Client也不会连上该Server, 不过通过程序也可以让其重注册,再次使得Client连接分布均匀。

