
-
配置Zookeeper
-
基本配置
-
clientPort
-
dataDir和dataLogDir
-
tickTime
-
存储配置
-
preAllocSize
-
snapCount
-
autopurge.snapRetainCount
-
autopurge.purgeInterval
-
fsync.warningthresholdms
-
weight.x=n
-
traceFile
-
网络配置
-
globalOutstandingLimit
-
maxClientCnxns
-
clientPortAddress
-
minSessionTimeout
-
maxSessionTimeout
-
集群配置
- 请保证集群中的每个Server都具有一致的集群配置。
-
initLimit
-
syncLimit
-
leaderServes
-
server.x=[hostname]:n:n[:observer]
-
cnxTimeout
-
日志配置
- 下面是一份简单的配置
-
配置Zookeeper集群
-
主要规则
-
可配置的Quorum
- 可通过下面的配置创建服务器组
- 如下配置,有3个Server组,每个Server权重为1,需要2个Server组的2个Server,或者4个Server才能形成一个Quorum, 若要构成多个Quorum,则需要5个Server:
- 为了防止上面的情况发生,可以通过weight(权重)来实现(即使只有一个数据中心,仍然可以形成一个Quorum):
-
观察者(Observers)
- 并在每个Server中配置:
-
重配置
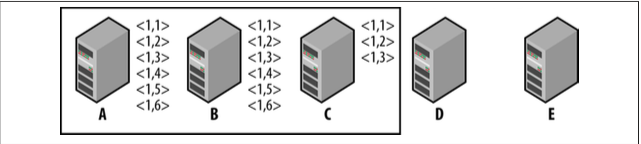
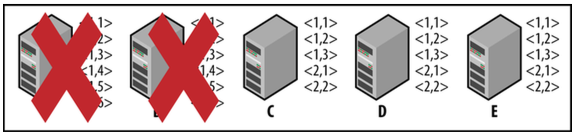
- 当Zookeeper集群不足以支撑Client的请求时,这时需要扩展更多的Zookeeper Server来提供服务,但这并不是很容易,如下面的情况:
- 这时可以停掉集群,重新配置A,B,C,D,E,再启动集群,但这可能发生问题,A,B由于启动慢,C,D,E形成了一个 Quorum
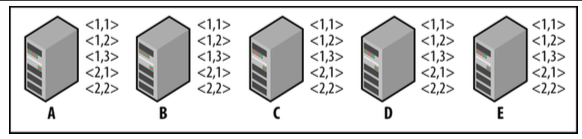
- 而当A,B启动完成后,C已经成为了Leader,C将告诉A,B删除事务<1, 4>,<1, 5>,<1, 6>, 并同步新的事务<2, 1>,<2, 2>:
- 然而,Zookeeper提供了重配置的操作,通过将部分配置移到一个动态文件(dynamicConfigFile)中来实现重配置, 如之前的静态配置为:
- 可以将需要动态配置的属性放到动态文件中,如clientPort,server等,这时静态文件配置为:
- dyn.cfg文件:
- 这时就可以通过以下命令来移除或增加新的Server:
- 重配置在Zookeeper3.5.0后被支持
-
管理客户端连接字符串
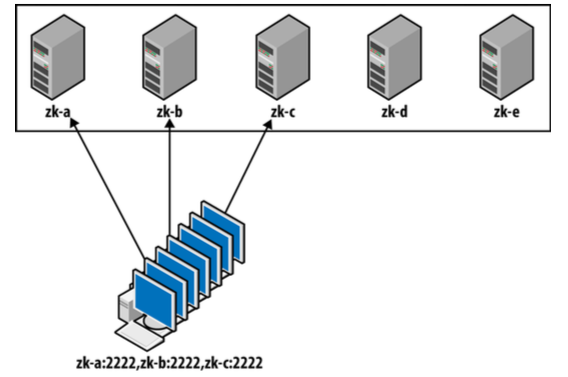
- 当服务器集群数目发生变化时,客户端的连接配置仍然是之前的Server列表,因此只能连接到已配置的Server列表,如:
- 但可以通过DNS,利用其一个hostname对应多个IP的特性,来实现客户端能访问集群中所有的Server,如:
-
配额(Quotas)
- 我们可以通过zkCli来设置配额,如:
- 当再次创建超额的数据时:
- 日志中将会有提醒信息:
-
文件系统布局和格式
-
事务日志
- Zookeeper会为事务日志预分配文件大小(即preAllocSize),如:
- 日志文件名称前缀数字代表epoch(如上面的23),后缀数字代表第一个zxid的十六进制。 对于日志文件中的内容,可以通过Zookeeper中的org.apache.zookeeper.server.LogFormatter来查看:
-
快照
- 快照文件命名格式类似于事务日志文件,如:
- 类似事务日志文件查看,可以通过org.apache.zookeeper.server.SnapshotFormatter查看快照文件
-
Epoch文件
- 除了事务日志,快照文件外,额外还有acceptedEpoch和currentEpoch, 记录Server正处于的epoch,如:
- 正好和事务日志文件的前缀名一致。
-
四字母命令
- Zookeeper提供了一些四字母命令来监控和监控系统,需通过telnet或nc来执行命令。
-
ruok
-
stat
-
srvr
-
dump
-
conf
-
envi
-
mntr
-
wchs
-
wchc
-
wchp
-
cons, crst
-
JMX监控
- 若要进行远程JMX监控,可以在zkServer.sh中加入参数配置,如:
- passwd文件,如:
-
工具
- 在Zookeeper的发行包中,contrib就自带了很多有用的工具。
-
zktreeutil
-
zktop
-
loggraph
- 这些工具都可以在Github上有具体的使用方法。
当Zookeeper集群在生产中变得愈发庞大时,如何能更好的管理和维护这些服务器,将是本文所要探讨的。
Zookeeper基本的配置都放在zoo.cfg文件中, 没有特别需求,每个Server可以共享同一份该文件。为了多个Server能够彼此区别, 在Zookeeper的data目录下会放置一个myid文件, 用一个唯一数字标识自己。配置参数通常可以配置在文件中,或者通过 -D的形式来指定,但配置文件的的属性具有更高的优先级。
Client连接Server使用的端口,如果Server没有设置clientPortAddress, Server将监听在所有网卡上,默认端口为2181。
dataDir用于存储内存DB的快照和Server的id,快照是在后台线程中进行写入的,不会锁住DB, 因此dataDir没有必要使用专门的设备。 dataLogDir用于存储事务日志,事务日志的写操作是十分敏感的,通常应该使用专门的设备。
tick是Zookeeper的基本时间测量单位(毫秒),它也决定了会话超时的桶(bucket)大小,默认为3000ms。
preAllocSize事务日志文件的预分配大小(kb)(zookeeper.preAllocSize)。当Server写入事务日志时, 会一次性申请preAllocSize大小的文件块,这会减少磁盘空间分配和元数据更新的开销,更重要的是减少了寻址的次数。 preAllocSize默认为64M。事务日志文件会随每一次快照后,新建另一个日志文件,如每次快照之间产生的事务不是很多, 那64M大小确实偏大,比如每1000个事务就进行一次快照,每个事务大概100字节,那preAllocSize设置为100KB要合理得多。 而默认的preAllocSize对于默认的snapCount,及事务日志平均512字节的情况是合理的。
snapCount即快照间的事务数量(zookeeper.snapCount),默认值为100000。 因为快照是比较影响性能的,但只要集群中的Server不是同时进行快照,就不会出现性能问题,出于这个原因, 实际快照的事务日志数将是一个接近snapCount的随机数。 如果上一次快照还没有结束,本次快照将等待上一次快照结束再开始。
autopurge.snapRetainCount表示Zookeeper清理快照时,需要保留的快照数。 Zookeeper会每隔一段时间,对快照进行垃圾回收, autopurge.snapRetainCount指定了需要保留多少个快照,默认值为3。
autopurge.purgeInterval表明了旧快照和日志清理工作的间隔时间(小时), 默认设置为0,这时必须手动执行zkCleanup.sh脚本进行清理工作。
fsync.warningthresholdms表明同步存储变化的时间超过该值, 如果系统同步调用sync花费太多时间,将严重影响系统性能,当花费的时间超过该值时,将发出一个提醒。
和group选项一起使用,当正在形成法定人数时, 这将分配一个权重n给Server x,n将作为投票的权重值,默认为1。
用于记录Zookeeper操作的跟踪文件,格式为traceFile.year.month.day, 须设置为requestTraceFile才能生效,这可能会引起CPU和磁盘争用, 应避免与日志文件dataLogDir一样,该配置不用加上zookeeper前缀。
globalOutstandingLimit(zookeeper.globalOutstandingLimit)限制Zookeeper最大的未完成请求数,默认为1000。 Client提交请求的速度可以比Server处理请求的速度快,这将导致请求被排队,最终导致Server内存溢出,为了防止这种情况发生, 一旦客户端排队请求达到该值,Server将对客户端请求进行控制。但globalOutstandingLimit 并不是一个硬性限制,每个Client必须至少有一个未完成的请求,或者连接正开始超时。因此,在未完成请求数达到该值后, 只要Client没有挂起的请求,Server则会读取来自Client的连接。
允许每个IP最大的并发Socket连接数,默认是60,但这个限制是针对某个Server,而不是整个集群。
Client连接Server的网络地址,通常是内网。
当Client创建了Connection,并设置了特定的超时时间,但超时时间不将低于minSessionTimeout(ms), 默认为2 * tickTime,该值过低会导致错误地判断Client崩溃,同理,过高将延迟判断Client崩溃。
当Client创建了Connection,并设置了特定的超时时间,但超时时间不将高于maxSessionTimeout(ms), 默认为20 * tickTime
Follower初始化连接Leader的超时时间(initLimit * tickTime)。 当Follower落后Leader很多时,将需要传输很多数据,会耗费比较多的时间,因此 initLimit大小应该取决于Follower和Leader的 数据传输量和网络传输速度。
Follower同步Leader的超时时间(initLimit * tickTime), 这将取决于网络延迟和吞吐量。
通过yes或no指明Leader是否可以接受Client连接(zookeeper.leaderServes)。
配置集群中的Server。(该配置所有Server应保持一致) x表示Server ID, hostname表示Server主机名, n表示连接端口,第一个表示发送事务的端口(默认2888),第二个表示Leader选举使用的端口(默认3888), observer标识该Server为Observer。
在Leader选举期间,打开连接的超时时间(zookeeper.cnxTimeout)。 在Leader选举过程,Server互相连接,该值将决定Server在尝试重新连接之前,需要等待的时间。
Zookeeper使用SLF4J作为日志抽象层,默认使用 Log4J作为日志实现,需在类路径下放置log4j.properties。
zookeeper.root.logger=INFO, CONSOLE
zookeeper.console.threshold=INFO
zookeeper.log.dir=.
zookeeper.log.file=zookeeper.log
zookeeper.log.threshold=DEBUG
zookeeper.tracelog.dir=.
zookeeper.tracelog.file=zookeeper_trace.log
log4j.rootLogger=${zookeeper.root.logger}
log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Threshold=${zookeeper.console.threshold}
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.layout.ConversionPattern=%d{ISO8601} [myid:%X{myid}] -
...
log4j.appender.ROLLINGFILE=org.apache.log4j.RollingFileAppender
log4j.appender.ROLLINGFILE.Threshold=${zookeeper.log.threshold}
log4j.appender.ROLLINGFILE.File=${zookeeper.log.dir}/${zookeeper.log.file}
log4j.appender.ROLLINGFILE.MaxFileSize=10MB
log4j.appender.ROLLINGFILE.MaxBackupIndex=10
log4j.appender.ROLLINGFILE.layout=org.apache.log4j.PatternLayout
当一个集群有足够的Zookeeper Server开始处理请求时,我们称该服务器集为一个Quorum。 我们必须要求一个Quorum至少一半数的Server构成, 若要构成多个Quorum,那这些Quorum必须有相交的Server,这一点是显然满足的。
为了构成一个Quorum,投票时需要来自过半的服务器组及过半的服务器的投票数, 也就是说,假若集群中有3个服务器组,每个组有3个服务器,每个Server的权重为1,为了形成一个Quorum, 则需要4个Server的投票:来自组1的两个Server和2个来自不同组的Server。用数学描述就是, 假若有G个Server组,需要的Server来自G的一个子集G'(|G'| > |G|/2), 另外,对于G'中的每个g,需要g的子集g'的权重W',至少是g的总权重W一半(Wʹ > W/2 )。
group.x=n[:n] // x代表服务器组编号,n标识server ID(用:隔开)
group.1=1:2:3
group.2=4:5:6
group.3=7:8:9
通常在部署Zookeeper时,一个组作为一个数据中心是比较合理的。比如我们有三个数据中心, 其中两个都部署3个Server,另外一个只部署1个Server,若其中一个数据中心不可用了, 另外两个也能构成一个Quorum, 这种配置的优点是7台Server中任意4台都能构成一个Quorum, 缺点是,不同数据中心的服务器数目不均衡,另一个缺点就是,一旦其中一个数据中心不可用, 则不容许其他数据中心出现崩溃。
比如,为两个数据中心分别部署3个Server,并将它们分为同一组group.1=1:2:3:4:5:6, 每个Server权重都默认为1,这时只要有4个Server就能构成一个Quorum, 但若其中一个数据中心崩溃,即使其他3个Server正常,也不能构成Quorum。 但假如分配给Server 1更大的权重(weight.1=2),假如Server 1在D1数据中心上, 即便其他数据中心都崩溃了,Server 1仍能得到其他2个Server的投票,总共4票,同样能构成Quorum。
观察者在Zookeeper集群中并不参与保证状态有序更新的投票协议,要配置一个Observers,需在Observers Server的配置文件中加入:
peerType=observer
server.1:localhost:2181:3181:observer
tickTime=2000
initLimit=10
syncLimit=5
dataDir=./data
dataLogDir=./txnlog
clientPort=2182
server.1=127.0.0.1:2222:2223
server.2=127.0.0.1:3333:3334
server.3=127.0.0.1:4444:4445
tickTime=2000
initLimit=10
syncLimit=5
dataDir=./data
dataLogDir=./txnlog
dynamicConfigFile=./dyn.cfg
server.1=127.0.0.1:2222:2223:participant;2181
server.2=127.0.0.1:3333:3334:participant;2182
server.3=127.0.0.1:4444:4445:participant;2183
reconfig -remove 2,3 -add server.4=localhost:2111:2112;2113,6=localhost:2114:2115:observer;2116
Zookeeper对节点的数量及其存储的数据量会有一定的限制,并且也允许自由配置这些限制, 一旦超过这些限制,日志中将记录警告信息,但是操作还是会被继续执行。 为了创建应用/application/superApp的配额, 需要为节点/application/superApp创建两个子节点: zookeeper_limits和 zookeeper_stats。 节点数量的限制叫做计数(count), 数据量的限制叫做字节(bytes)。 zookeeper_limits和 zookeeper_stats 的配额都被定义为count=n,bytes=m, zookeeper_limits时, n和m表示警告被触发的级别(如果其中一个为-1,则不将被触发), zookeeper_stats时, n表示子树中节点的数量,m表示子树中节点的数据量(不包括节点元数据)。
[zk: localhost:2181(CONNECTED) 2] create /application ""
Created /application
[zk: localhost:2181(CONNECTED) 3] create /application/superApp super
Created /application/superApp
[zk: localhost:2181(CONNECTED) 4] setquota -b 10 /application/superApp
Comment: the parts are option -b val 10 path /application/superApp
[zk: localhost:2181(CONNECTED) 5] listquota /application/superApp
absolute path is /zookeeper/quota/application/superApp/zookeeper_limits
Output quota for /application/superApp count=-1,bytes=10
Output stat for /application/superApp count=1,bytes=5
create /application/superApp/lotsOfData ThisIsALotOfData
2015-06-20 23:57:15 DataTree [WARN] Quota exceeded: /application/superApp bytes=21 limit=10
之前已经介绍过,Zookeeper中通过两种方式存储数据: 事务日志和快照, 这都将以文件存储在本地文件系统中,事务日志文件是事务处理的关键步骤,所以强烈建议为事务日志指定特定的目录。
-rw-r--r-- 1 haolin staff 64M Jun 21 20:50 log.2300000001
java -classpath zookeeper-3.4.6/zookeeper-3.4.6.jar:zookeeper-3.4.6/lib/log4j-1.2.16.jar:zookeeper-3.4.6/lib/slf4j-log4j12-1.6.1.jar:zookeeper-3.4.6/lib/slf4j-api-1.6.1.jar org.apache.zookeeper.server.LogFormatter log.2300000001
ZooKeeper Transactional Log File with dbid 0 txnlog format version 2
6/21/15 8:15:27 PM CST session 0x14e160a4a720000 cxid 0x0 zxid 0x2300000001 createSession 30000
6/21/15 8:16:58 PM CST session 0x14e160a4a720000 cxid 0x3 zxid 0x2300000002 error -101
6/21/15 8:17:03 PM CST session 0x14e160a4a720000 cxid 0x4 zxid 0x2300000003 create '/test,#2222,v{s{31,s{'world,'anyone}}},F,6
6/21/15 8:17:20 PM CST session 0x14e160a4a720000 cxid 0x5 zxid 0x2300000004 create '/test/test1,#2249,v{s{31,s{'world,'anyone}}},F,1
6/21/15 8:50:32 PM CST session 0x14e160a4a720000 cxid 0x0 zxid 0x2300000005 closeSession null
EOF reached after 5 txns
-rw-r--r-- 1 haolin staff 308B Sep 30 2014 snapshot.600000001
-rw-r--r-- 1 haolin staff 296B Sep 30 2014 snapshot.700000001
快照文件是不用预分配的,其大小真实反映了数据大小,后缀名标识了快照开始时的zxid, 当Serer从快照进行恢复时,必须通过zxid进行重新事务广播。
java -classpath zookeeper-3.4.6/zookeeper-3.4.6.jar:zookeeper-3.4.6/lib/log4j-1.2.16.jar:zookeeper-3.4.6/lib/slf4j-log4j12-1.6.1.jar:zookeeper-3.4.6/lib/slf4j-api-1.6.1.jar org.apache.zookeeper.server.SnapshotFormatter snapshot.600000001
ZNode Details (count=4):
----
/
cZxid = 0x00000000000000
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x00000000000000
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x00000000000000
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x00000000000000
dataLength = 0
----
...
Session Details (sid, timeout, ephemeralCount):
0x148c24ebbad0000, 40000, 0
cat currentEpoch
35
查询Server的状态信息,只要Server运行着就会返回imok,即使其不能与其他Server互连, 仍然会返回imok,因此建议使用 stat。
查询Server的状态和当前的连接信息,如果是Learder或者Follower,会包含最近的zxid。
和stat类似,但不提供连接信息。
获取当前激活的会话信息,及其过期时间,该命令只能在Leader使用。
查看Server启动时的基本配置信息
查看Java环境参数
查看比stat更详细的信息,对于Leader会更有
查看Server跟踪的监听器简要信息。
查看Server跟踪的监听器详细信息。
查看Server跟踪的监听器,并按照节点路径分组。
cons查看Server的详细连接信息, crst重置所有的连接计数为0。
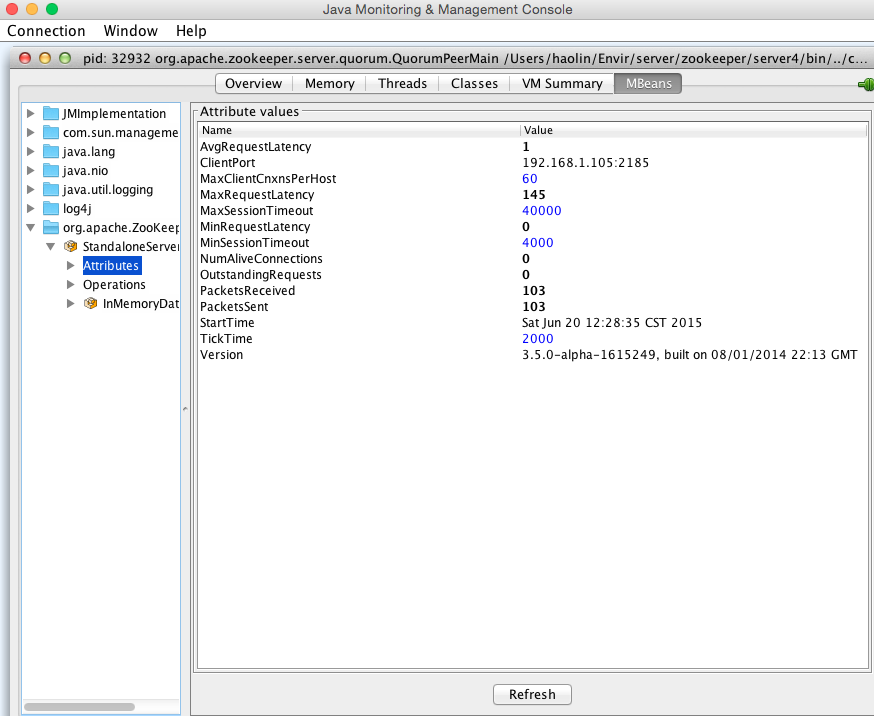
Java自带的监控工具jconsole就可以对Zookeeper进行线程,类实例,VM状态等进行很友好地监控,如:
SERVER_JVMFLAGS="-Dcom.sun.management.jmxremote.password.file=passwd -Dcom.sun.management.jmxremote.port=55555 Dcom.sun.management.jmxremote.ssl=false \Dcom.sun.management.jmxremote.access.file=access"
# user password
admin <password>
导入和导出Zookeeper数据。
查看Zookeeper的负载情况,类似*nix的top。
日志可视化。

