
-
请求,事务和标识符
-
Leader选举
- 当Server接收到投票后,将根据以下规则来改变自己的投票:
- 可通过下面的图阐述上面的投票过程
- 但有可能因为如网络延迟等问题,导致选举Leader不一致,如
- 尽管s2选举了不同Server为Leader,但这并不会服务表现得不正确,因为s3不会响应s2的投票选举。 最终s2将由于没有得到s3的响应而超时,并再次尝试。如图
-
Zab: 广播状态更新
- 假设有一个激活的Leader, 并有支持其领导权的几个Follower, 那提交事务的协议将变得很简单,分为两阶段提交
- 如图,阐释了两阶段提交:
- Follower在确认提议前,需要做一些额外的检查, 如需要检查来自Leader的提议必须是有序的, Zab也保证两个重要的特性:
- 第一点保证了事务在不同的Server间以相同的顺序提交,第二点保证了Server不会出现跨事务。 每个zxid中都包含了一个叫epoch(时期)的元素, 每发生一次Leader选举,该值将增加,同样的Sever可以在不同的时期成为Leader, 然而时序问题和消息丢失 将有可能导致事务提交乱序或跨事务问题,为了解决这个问题,Zab也保证:
-
观察者
-
服务器架构
-
单机服务器
- 在Zookeeper中最简单的管道就是单机服务器(ZooKeeperServer,没有备份), 这种类型的服务器拥有三个请求处理器: PrepRequestProcessor, SyncRequestProcessor, FinalRequestProcessor
-
Leader服务器
- 当切换到Quorum模式(LeaderZooKeeperServer)后,服务器管道将发生变化,如图
-
Follower和Observer服务器
- 如图,为Follower服务器的处理器管道
-
本地存储(Local Storage)
- 之前提过事务日志和快照,并且SyncRequestProcessor作为写操作的处理器,接下来会具体介绍这些。
-
日志和磁盘使用
-
快照
- 比如,像下面这样的步骤有可能导致快照数据不一致:
-
服务器与会话
- 当会话的过期时间更新时,如何计算其下一个桶(bucket)呢:
-
服务器和监听器
- 之前介绍过,监听器是一次性触发的,并且每一个监听器都被特定的操作触发。服务器端通过 WatchManager实例负责维护监听器列表,并触发它们。 所有Server(Leader, Follower, Observer)都以相同的方式处理监听器。
-
客户端
-
序列化
- Zookeeper使用Jute来对消息和事务进行序列化处理。 Jute使用zookeeper.jute 定义了所有消息和文件的记录,比如创建事务的定义:
当应用中使用了Zookeeper作为我们的分布式协调工具时, 此时就需要对其进行各种管理,监控等等运维工作, 本文将主要介绍Zookeeper的内部组件, Zookeeper内部如何工作,使用的协议, 以及当提供高性能服务时的容错机制等。
Zookeeper服务器会在本地处理读请求(如exists, getData, getChildren等)。 由于是本地处理读请求,所以Zookeeper可以很快的处理读请求,因此我们可以通过加更多的Server到Zookeeper集群中, 有效提升处理读请求的吞吐能力。
而Client的写请求(如create, delete, and setData等)将被转发给集群中的 Leader来处理。 Leader处理请求,并更新集群状态的过程叫做 事务(Transaction)。 举个例子,Client提交了对节点/z的 setData的请求,这将改变节点 /z和增加其版本号, 因此该请求的事务将包括两个重要的地方: 节点的新数据和节点的新版本号。
一个事务被当作一个单元,本质上,事务内的所有操作应该被原子地执行。 上面的setData例子,若更新了数据,但节点的版本号未更新,将发生错误。 因此,当Zookeeper集群执行事务时,会保证事务中的所有操作被原子执行并且不会被其他事务干扰。但是不像关系型数据库, Zookeeper并没有回滚机制,而是确保事务的步骤不会互相干扰。之前很长一段时间, Zookeeper采用单线程模式来保证事务被有序执行, 而最近Zookeeper开始支持以多线程的方式来加速事务处理。 一个事务是幂等的,就是说,执行两次同样的事务会得到同样的结果, 甚至可以多次执行多个事务,只要每次以相同的顺序执行它们,在恢复中,会利用幂等这个特性。
当Leader创建一个事务后,会分配一个事务标识符(zxid), Zxids用于标识事务,这样Zookeeper服务器可以有序地执行Leader创建的事务。 在选举Leader时,Server之间也会交换zxid。 Zxid是一个long型整数,由两个部分组成: epoch和counter,每部分占32位, 它们的作用会在Zab协议中细说。
Leader是由集群中的Server选举出来的,并且持续得到集群的支持。 Leader的作用就是组织Client提交的更新请求: create, setData, delete。 Leader将请求转变成一个事务, 然后通知集群中的Follower有序地执行这些事务。
为了获取Leader权,必须获得集群中法定人数(quorum)的Server的投票。 每个Server都以LOOKING状态开始, 并且必须找到选举一个新的Leader或者已经存在的Leader。 如果Leader已经存在,那么其他Server将通知新的Server,哪个Server是Leader, 这时,该Server将连接到Leader,确认自己的状态和Leader一致。 如果集群中的Server都是LOOKING状态, 它们就必须选举出一个Leader,通过交换消息作出Leader选择, 最终获得选举权的Server将进入LEADING状态, 其他Server则进入FOLLOWING状态。
选举Leader的消息被称为Leader选举通知, 协议非常简单,当Server进入LOOKING状态时, 将批量发送通知消息给集群中的Server,该消息将包含当前的 投票 (由Server标识符(sid)和最新的事务标识(zxid)组成), 因此,(1, 5)则表示该Server的sid为1,最近执行的事务id为5。 (对于Leader选举,zxid是一个纯数字,而在其他协议中,其有可能代表一个时段和计数器)。
1. 若voteId和voteZxid
作为当前接收方Server的sid和zxid,而
myZxid和mySid
作为当前接收到的投票的sid和zxid。
2. 如果(voteZxid > myZxid)或者(voteZxid=myZxid,并且voteId>mySid),则保持当前的投票。
3. 否测,将myZxid赋值给voteZxid,mySid赋值给Zxid。
总之,最终最新的Server将赢得Leader权,因为它具有最新的zxid。 若多个Server具有同样的zxid,那么sid最大的将取得Leader权。
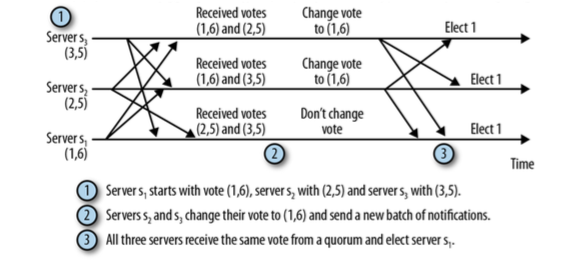
1. s1开始投票(1, 6), s2开始投票(2, 5), s3开始投票(3, 5)
2. s2和s3更新它们的投票为(1, 6),并发出新的投票通知。
3. 3个Server均收到法定人数(quorum)的相同投票,因此最终选择s1为Leader。
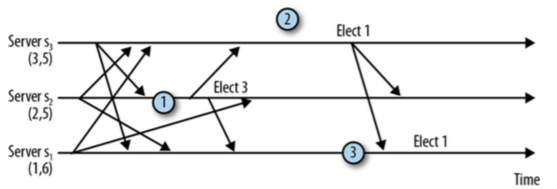
1. s2首先接收到s3的投票(3, 5),于是改变自己的投票,因此选举了s3
2. s3收到投票(1, 6),但耗费了一些时间来发送投票通知
3. s1一旦收到s3的投票通知,将选举自己为Leader。
1. s2收到来自s3更高的投票,更新自己的投票
2. s3收到来自s1更高的投票,更新自己的投票
3. s2延迟选举s3,相当于多了一次收到s1投票的机会,然后选举s1
当接收到写请求时,Follower会将其转发给Leader,
Leader将以事务的形式执行该请求,并且广播执行结果以更新状态,
一个事务包含了当事务提交时,Server中的目录树状态改变集。
接下来的问题就是Server如何决定事务是否已经被提交,这涉及到
Zab协议: Zookeeper原子广播协议。
1. Leader向所有Follower发送PROPOSAL消息p
2. 一旦Follower接收到消息p,将以ACK响应Leader,表示自己接受Leader的提议
3. 当Leader接收到法定人数的确认消息后,将发送消息通知Follower提交该事务。
1. 如果Leader以顺序广播了事务T和T',那么Server必须先提交事务T,再提交事务T'。
2. 任何Server以T和T'顺序提交了事务,那么其他Server也必须以这样的顺序提交事务。
1. 在Leader广播新的事务之前,必须已经提交所有之前时期(epoch)没有提交的事务。
2. 在任何时刻,都不会有两个Server有法定人数的支持者。
为了实现第一个需求,Leader在没有得到法定人数(quorum)Server的确认时,是不能开启新的时期(epoch)的。 一个时期的初始状态中必须包含所有之前提交的,和被接受但没提交的事务。
第二点显得有些困难,没办法单独地阻止两个Leader被选举。也就是说,Leader l正在广播事务, 但在某个时间点,法定人数Server Q认为Leader l已经崩溃, 并且选举了新的Leader l', 假设事务T在Q抛弃Leader l时正在被广播, 并且Q的一个严格子集已经成功记录了事务T,在l'被选举后, 做够多的进程(非Q中的)也记录了事务T,并且对于事务T已经形成了法定人数(Quorum), 这种情况下,即使事务T在l'被选举之后提交,不用担心,这并不是bug。 Zab协议通过保证l'的法定人数支持者至少包含一个赞成过事务T的Follower,来保证事务T是l'提交事务的一部分。 这儿的关键点就是,l和l'不会同时具有法定人数的支持者。下图阐释了这种场景:
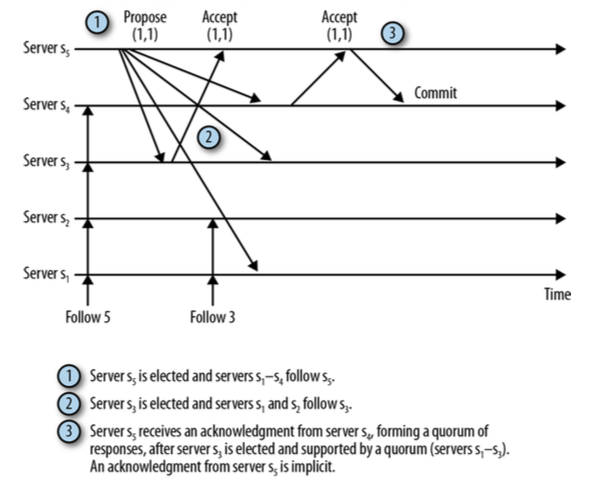
图中s5是Leader l,s3是Leader l', 法定人数Q由s1~s3组成,事务T的zxid为(1, 1)。 当收到第二个确认信息后,s5会发送提交消息告诉s4提交事务,而其他Server一旦开始跟随s3,将忽略来自s5的消息, 注意s3确认了(1, 1),因此当它获取领导权时,是知道事务T的。
和Follower某些地方一样,Observer也会提交来自 Leader的提议,但并不参与投票过程,它们仅仅是学习INFORM消息中的提议。 参与投票的Server叫PARTICIPANT,可以是 Leader或Follower, 相反不参与投票的Server叫OBSERVER。 需要OBSERVER的主要原因是增强读请求的可扩展性, 因此可以在不牺牲写请求吞吐量的前提下,增强服务器的读请求处理能力, 当然增加OBSERVER,每次提交事务会带来额外的消息发送, 然而,相比增加PARTICIPANT(会降低系统写吞吐),这点损耗是微乎其微的。
Leader,Follower,Observer 都是必不可少的服务器。我们将服务器的实现抽象为请求处理器(request processor), 可以将每一个请求处理器想象为处理请求中的一个元素,当请求被服务器请求管道中所有的处理器处理完毕后,该请求就完成了。
// ZooKeeperServer.java
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
((SyncRequestProcessor)syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor)firstProcessor).start();
}

PrepRequestProcessor将接受并执行客户端请求, 并生成一个事务(读请求将不会生成事务), SyncRequestProcessor负责持久化事务到磁盘, 本质上,是将事务有序追加到事务日志中,并且频繁生成快照。 当请求中包含事务时,FinalRequestProcessor 则将进行Zookeeper目录树的更新,否则将读取目录树的数据,返回给客户端。
// LeaderZookeeperServer
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor toBeAppliedProcessor = new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader());
commitProcessor = new CommitProcessor(toBeAppliedProcessor,
Long.toString(getServerId()), false);
commitProcessor.start();
ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this,
commitProcessor);
proposalProcessor.initialize();
prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor);
prepRequestProcessor.start();
firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor);
}
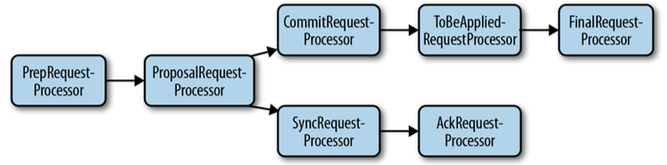
ProposalRequestProcessor准备提议,并发送给Followers。
ProposalRequestProcessor会转发所有的请求给
CommitRequestProcessor,并且将写请求转发给
SyncRequestProcessor。
SyncRequestProcessor工作原理同单机服务器差不多,持久化事务数据到磁盘,
并以触发AckRequestProcessor就结束,
AckRequestProcessor则用于生成确认信息。
ProposalRequestProcessor另一个后续处理器是CommitRequestProcessor,
CommitRequestProcessor将提交已经收到足够确认的提议,
而确认信息是在Leader中的processAck()中处理的。
ToBeAppliedRequestProcessor将迁移将被执行的提议(包括已经被法定人数确认和等待被执行的提议,但不对读请求做任何处理)。
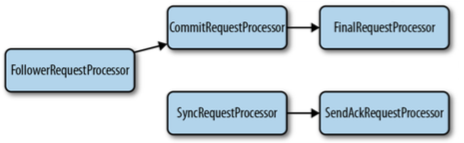
FollowerRequestProcessor用于接收和处理客户端请求,
并转发请求给CommitRequestProcessor,
此外会将写请求转发给Leader,
将读请求直接转发给FinalRequestProcessor。
当Leader收到一个新的写请求时,将生产一个提议,并转发给
Follower,
Follower一旦接收到请求,将其记录到磁盘,并转发给
SendAckRequestProcessor,SendAckRequestProcessor
确认向Leader确认提议,当Leader接收到足够的确认信息后,
将发送提交信息给Follower(同时发送INFORM信息给Observer)
Follower一旦接收到提交信息,将通过CommitRequestProcessor来处理。
Server使用事务日志来持久化事务,在接受提议前,Server(follower或者leader)将有序追加提议中的事务到事务日志文件中,
有时也会关掉当前文件IO,滚动创建一个新的日志文件。由于写操作是比较耗时间的,Zookeeper采用了一些加快写操作的措施:
组提交(Group Commits)和填充(Padding)。
组提交(Group Commits)会将几次写操作统一执行,这样只需对磁盘文件进行一次定位。
填充(Padding)是指预分配一块磁盘空间到一个文件,这也防止进行顺序写操作时,
不会因为申请磁盘空间而影响写性能。
快照即Zookeeper目录树数据的副本。 当Server接收请求的同时也会进行快照处理,即当进行快照时,目录树数据有可能发生变化, 这样快照并不是数据实时的,当然也没有必要是实时的。
1. Start a snapshot.
2. Serialize and write /z = 1 to the snapshot.
3. Set the data of /z to 2 (transaction T).
4. Set the data of /z' to 2 (transaction Tʹ ).
5. Serialize and write /z' = 2 to the snapshot.
这时,快照数据为 /z = 1 和 /z' = 2。 但事实上,没有任何时间点存在 /z = 1 和 /z' = 2, 这不将是问题所在,因为服务器会事务重播。 服务器会在执行快照时,用最新的事务对快照进行标记--叫做TS。 如果服务器最终加载了快照,它会重播所有事务日志中处于TS之后的事务(这里即是T和T'), 在快照的基础上,重播事务T和T',节点数据会成为/z = 2 和/z' = 2。 但再次执行事务T和T'会不会带来什么问题呢?之前提到过,事务都是幂等的 (只要事务以相同的顺序执行,就会得到同样的结果),因此不会带来什么负面影响。
会话是Zookeeper中的一个重要抽象。 时序保证, 临时节点, 和监听器与会话紧密耦合, 因此会话跟踪机制对于Zookeeper来说非常重要。
Zookeeper最重要的任务之一就是会话跟踪。 单机模式下,服务器将跟踪所有的会话,集群模式下,Leader将会跟踪会话, 但两种模式都会使用同样的会话跟踪器(SessionTracker和SessionTrackerImpl), 而Follower负责将已连接的Client的会话信息转发给Leader(LearnerSessionTracker)。
为了保持会话存活,Server需要接收心跳,心跳以新请求或者PING消息的形式进行 (LearnerHandler.run()),这两种形式下, Server将通过更新会话过期时间保持会话(SessionTrackerImpl.touchSession())。 在集群模式下,Leader会想Learners发送PING消息,Learners然后发送回最近PING之后的会话列表。 Leader会每隔半个tick(Zookeeper中最小的时间单位)发送一次PING命令,比如,若tick为2秒, 那么Leader将每隔1秒发送一次PING命令。
管理会话过期的两个关键点。 其中有一个叫过期队列(ExpiryQueue)的数据结构, 它将会话保存在内部的桶(bucket)里,每一个桶对应一段时间范围内将被认为过期的会话, Leader将一次性终止该桶内的会话。为了决定哪个桶被终止,将有一个线程来检查该队列, 并计算出下一次过期的时刻。
为了维护这些桶(bucket),Leader将时间分为expirationInterval单位, 并且当过了会话过期时间后,会把会话分配到后面的桶(bucket),本质上是讲会话挪到下一个更大的过期时间桶(bucket)里。
(expirationTime / expirationInterval + 1) * expirationInterval
DataTree中有两个监听器,一个监听子节点,另一个监听数据。 当处理一个设置监听器的读操作时,该类会将监听器添加到监听器列表中,当处理一个事务时, 该类会检查是否有监听器被触发,如果有监听器被触发,该类会调用WatchManager的触发器方法。 添加监听器和触发监听器都将在FinalRequestProcessor
服务器端被触发的监听器会被广播到客户端,由类ServerCnxn负责。 它代表了客户端与服务器之间的连接,并且实现了Watcher接口。 Watcher.process方法会序列化监听事件,并发送给客户端, 客户端接收到序列化后的事件,反序列化后传递给我们的应用。
客户端主要有两个类: Zookeeper和ClientCnxn。 客户端应用必须使用Zookeeper创建会话,并且获得服务端产生的唯一标识。 ClientCnxn则管理客户端与服务端的socket连接,它维护了一个服务器列表, 当一个Server不可连接时,可以自动连接其他可用的Server。
...
class CreateTxn {
ustring path;
buffer data;
vector<org.apache.zookeeper.data.ACL> acl;
boolean ephemeral;
int parentCVersion;
}
...

