
Zookeeper深入理解(二)(编程实践之故障处理)
2015 年 03 月 10 日
zookeeper
- 在使用Zookeeper中主要可能有三个地方会发生故障: Zookeeper服务本身, 网络问题, 和应用进程问题。 但要找出是哪个地方发生了故障,却不是那么容易。
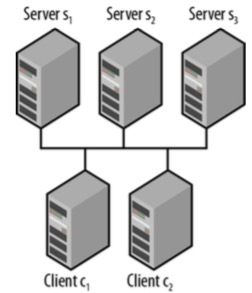
- 如下面这个简单的分布式应用,有2个应用进程和由3个Server组成的Zookeeper服务。 应用将随机连接到一个Server,Server使用内部协议进行状态同步, 使Client看到一个一致的视图。
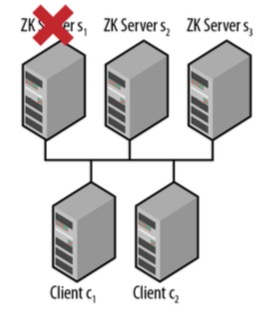
- 然而如果其中一个Server(如Server 1)崩溃了,我们要如何检查不同的故障问题呢? 比如,假设网络崩溃了,那么C1要怎么区别是 网络问题 还是Zookeeper服务问题呢? 如果没有网络问题,C1将能连接到其他正常的Server,但如果不能连接到任何Server, 则有可能是网络问题或者Zookeeper服务不可用。
- Zookeeper会出现两种故障: 可恢复的和不可恢复的。 可恢复的的故障是相对正常的,比如短暂网络停顿和Server问题会引起这种故障。 而不可恢复的的故障则更麻烦,这种故障会使得Zookeeper服务变得不可操作。 处理这种故障,最简单通用的方式是退出应用,引起这类故障有可能是会话超时, 网络中断超过了会话超时设置时间和认证失败。
-
可恢复故障
- Zookeeper会对所有连接它的Client表现出一致的状态,当一个Client收到Zookeeper的一个响应时, 它会相信其他Client收到的响应将是一致的,但如果ZK Client Library与Zookeeper服务断开连接, 将不能再保证信息的一致性,这时ZK Client Library将发布 Disconnected事件和ConnectionLossException异常。 当然,ZK Client Library会尽力尝试摆脱这种情形,它将持续尝试连接另一个Server,直到和Server重新建立连接, 一旦会话建立,Zookeeper将生成SyncConnected事件并开始处理请求, 这是Zookeeper将重新注册之前注册的监听器,并且对于在连接断开期间发生的变化,生成监听事件。
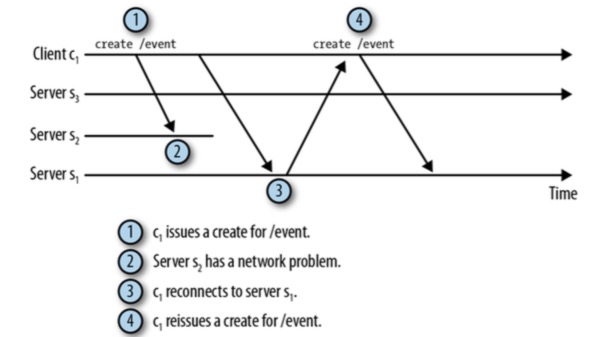
- 典型的Disconnected事件和ConnectionLossException 异常都是Zookeeper服务器故障。下图阐述了这种问题
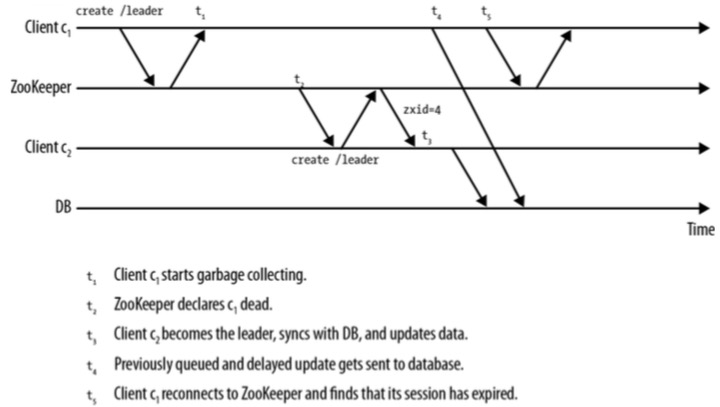
- 如果Client没有任何待处理的请求, Connection Loss很少会中断Client,除了发生 Disconnected事件,接着 SyncConnected事件外,Client不会收到任何状态改变通知。 但是当Client有待处理的请求时,则要麻烦得多。比如下面的场景
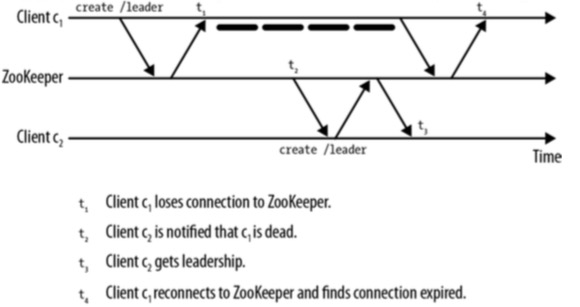
- Client c1将称为Leader,但是在t1时刻丢失了连接,但知道t4时刻它才知道自己已经被声明为崩溃,同时它的会话在t2时刻已经过期, 并且在t3时刻,Client c2变成了Leader,即t2~t4,Client c1不知道自己已经被声明为崩溃并且Leader已经转变为Client c2。 因此,当应用收到Disconnected事件时,直到应用再次连接上Zookeeper前,应该暂停作为Leader的操作, 正常情况下,重连接操作会很快。
-
exists监听和Disconnected事件
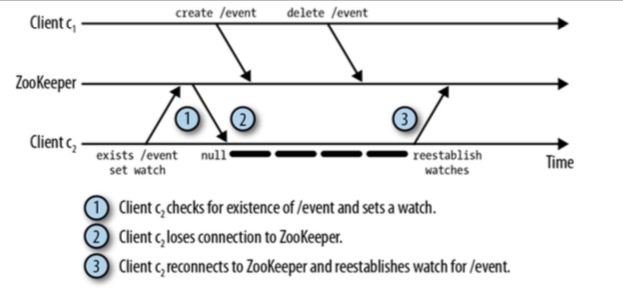
- 为了让会话断开和重连能够更无缝一些, ZK Client Library将在新的server上重建任何存在的监听器。 当ZK Client Library连接Server时, 它会发送未触发的监听器列表和最新的zxid给Server, Server会检查监听器及其对应的节点的更新时间戳,如果节点的更新时间戳在该zxid之后, Server将触发该监听器。但要排除exists操作,因为 exists可以监听一个不存在的节点。 但还是会出现丢失创建事件的情况,如下图,Client c2就丢失了节点/event创建的事件。
-
不可恢复的故障
- 不可恢复的故障通常是由于会话过期导致, 或者是已授权的会话不再被授权。这种两种情况,Zookeeper将丢弃会话状态。 处理不可恢复的故障最简单的办法就是终止进程和重启, 这使得进程可以恢复,并且通过新的会话重新初始化其状态。
-
Leader选举和外部资源
- 只要Client通过Zookeeper进行交互,Zookeeper将对它们呈现一致的状态, 但如果通过外部设备交互,则可能不会受Zookeeper保护,比如在负载比较大的主机上。 当Client进程所在主机负载过重时,它将开始 内存交换, 不稳定, 或者由于过度使用资源而发生大延迟。 一方面这会影响与Zookeeper交互的及时性,并且Zookeeper内部Server之间也不能及时发送心跳, 另一方面该主机上的本地线程调度引起不可预知的调度,比如下面的例子
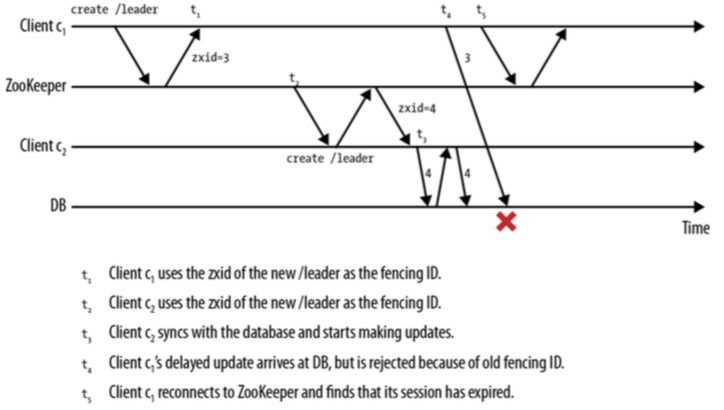
- 要解决上述这种对外部资源访问冲突的问题,我们可以用fencing这种技术。 即在访问外部资源时,Client需要持有一个访问Token,当外部资源持有的Token更高时,则拒绝Client访问,如
- 但这需要改变Client和外部资源的协议,即必须在协议中加入一个token(如图中的czxid)。 有些外部服务器可能提供了锁机制来解决这种问题,但还是有可能出现, 持有锁的Client被Zookeeper声明为了死亡,这时锁不能释放,从而阻止其他新的Leader获取锁。 但使用资源锁,要更实际一些。
在生产中使用Zookeeper,我们难免会遇到无法预料的故障,通过本文将了解到Zookeeper的的几种故障问题,及其如何处理这些故障。


好人,一生平安。